MapReduce Algorithms
1. MapReduce 工作原理
一图胜千言:
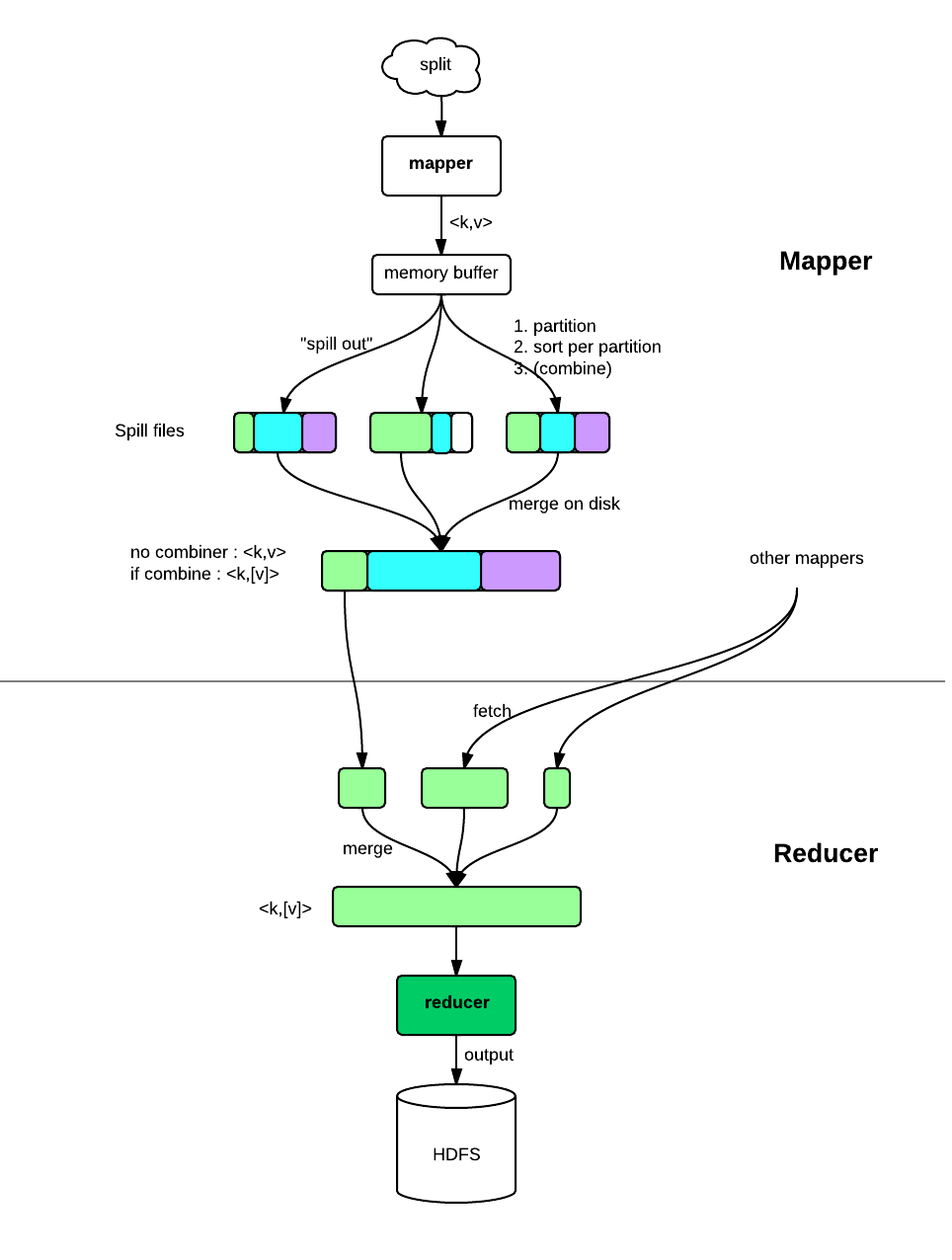
Mapper:
- Mapper 主要做些信息抽取、过滤等工作
- Mapper 数量由输入的 split 数决定,hadoop 会尽量选择靠近数据的节点运行 mapper 任务,因此可以认为 mapper 是 data-local 的
- 生成的
2. 常见算法的 MapReduce 实现
2.1 count / distinct
问题描述
其实就是 Hadoop wordcount 的例子:一堆文档,每个文档内一堆单词,统计每个单词出现次数。
解决
Mapper:
raw data --> 对每个碰到的单词,输出 <word,1>Shuffle 后可以保证同一个单词的所有键值对被一个 Reducer 处理
Reducer:
<word,[1,1,1...]> --(sum)--> <word,5>优化
用 combiner 合并 mapper 的输出,减少传输数据量:
Mapper:
raw data
1. --(mapper)--> <word1,1> <word1,1> <word2,1>
2. --(combine)--> <word1,2> <word2,1>distinct
distinct 就是集合去重,解决思路和 count 问题一样,不过不需要记录单词出现次数,键值对的 value 用 null 就可以了:
Mapper:
raw data --> <word,null>
Reducer:
<word,[null,null...]> --> <word,null>2.2 group by / aggregation
问题
实现类似数据库的 group by 及聚合函数的功能
实现
Mapreduce 的 shuffle 过程其实已经帮我们做了 group by 的工作,Reducer 拿到的输入就是 group by 后的结果,对其 value 应用聚合函数即可。
2.3 inverted index
问题
一堆文档,构造对应的倒排索引。
解决
思路和 wordcount 是一样的。
Mapper:
对一个文档中的每个单词,输出 <word,fileName>优化:可以用 Combiner 合并 Mapper 的输出。
Reducer:
Rducuer 的输入是 <word,[file1,file2...]>,直接输出就好了2.4 sort
问题
一堆文件,每个文件都有若干行,一行是一个数字,数字的范围是确定的,要求对其排序。
解决
利用 Reducer 拿到的输入是有序的这一特性,Mapper 和 Recuder 如果都用 identity function,那么每个 Reducer 的输出都是有序的,但 Reducer 之间无法保证有序。
如果用归并排序的思路, 那么最后还需要一个只有一个 Reducer 的 Mapreduce 任务对所有数据做一次 merge,这显然是无法接受的。
真正可行的算法是 桶排序。回顾桶排序的过程,它首先将数据分布范围划分为若干个桶,接着遍历一遍元素并分配到对应的桶中,然后对每个桶做一次排序,因为桶之间是有序的,所以不需要 merge。
在 Mapreduce 中,Partitioner 负责划分桶。举个例子,假设数据分布在 1 到 1w 之间,我们可以将其划分为 10 个桶,同时用 10 个 Reducer 处理每个桶内的数据,这样 Reducer 间就是有序的。为了实现这个效果,可以用一个自定义的Partitioner,将 Mapper 输出划分到上述 10 个桶内即可。
2.5 median / 第 k 大数
问题
一堆数字,找中位数或第 k 大数。
工作中遇见过一个类似的问题,场景是:
有一堆 Nginx 登陆日志,每条 log 都有一个时间点,要求找到一个时间点,使得该时间点之前的日志数占总日志数的 30%。
解决
在小数据量场景下,反复利用快速排序的分割可以在 O(n) 范围内找到第 K 大数。我们可以将这个思路扩展到分布式环境下:
- 用一个 MapReduce 任务统计所有日志的时间范围和日志总数;
- 随机选一个时间点,用一个新的任务统计该时间点之前和之后的日志数;
- 如果该时间点不满足要求,则根据 2 的结果找一个新的时间点,重复步骤2。
通常这类统计需求不要求非常精确,得到一个差不多的值就可以了。
2.6 top k
问题
求一堆数前 k 大的数。
解决
其实这个问题和上面的第 k 大数是一样的,可以用上面的思路解决,这里介绍一种 k 比较小时效率更高的算法。
如果数据量很小,求 top k 可以用一个小根堆维护 top k,堆顶为这最大的 k 个数中的最小元素,把所有数据过一遍,最后堆内就是所求值了。这个算法可以很容易地扩展到分布式的环境中:先求出每个 split 的 top k,合并这些元素再求一次 top k 即得结果。
Mapper:
维护一个小根堆,任务结束后对堆内每个元素输出一个键值对 <"",num1>, <"",num2> ...Reducer(数量为 1):
得到的输入为 <"",[每个 split 的 top k]>,对 value 求一次 top k 就可以了。该算法的优势在于只要一次 Mapreduce 任务即可,但缺点是只适用于 k 比较小的情况,如果 k 很大:
- 如果 k 大于每个 split 内包含的记录数,算法失效;
- Reducer 可能没有足够的内存容纳输入
2.6.1 出现次数 top k 的元素
比上面的 top k 问题多了一个步骤,要求出每个元素的出现次数。如果数据量比较小,可以用下面方法:
bitmap(如果不是数字的话则用 hashmap)+ 堆 / 快排的分割
bitmap / hashmap 用来统计元素的出现次数,堆用来保存当前 top k,只需一次遍历即可。 用快排的分割的话,要先统计出次数再分割,不只一次遍历。不要求精确的话,可以用 计数版本的 BloomFilter + 堆
BloomFilter 只保存了元素的次数,没有保存元素,因此只能边统计边记录 top k,一次遍历。
如果是大数据量就需要先用一个 hadoop 任务来分割,保证同一个元素的记录被分配到同一个 reducer,这样可以求出每个元素的出现次数;以这个任务的输出为输入,用上面提到的 top k 算法求出每个 split 的 top k;最后用一个 reducer 进行 merge,求出 top k 的 top k。
2.7 join
问题
join!
解决
通常有以下两种算法:
Replicated Join (Map Join, Hash Join)
如果 join 的一方数据量较小,可以载入内存,则可以用 Hadoop 的 Distributed Cache 将其分发到每个 Mapper 节点,在 Mapper 端进行 join。较小数据集在 Mapper 端通常被构造成一个 HashMap 以加速查找,因此 Mapper Join 实质上是一种 Hash join。
Repartition Join (Reduce Join, Sort-Merge Join)
如果两个数据集都很大,可在 Reducer 侧做 join:
Mapper 同时处理两个集合的数据,为遇到的每个记录生成一个键值对,key 是 join 的列值,value 除了该记录还需要一个 tag 表明它来自哪个集合:
raw data --> <key,(record,fromA)>, <key,(record,fromB)> ...Shuffle 后 Reducer 得到一个 key 对应的所有记录,无论是来自集合 A 还是 B。接下来 Reducer 用循环,根据 join 的类型对这些记录做连接即可。
该算法的关键在于 shuffle 阶段的排序,因此本质上是一种 Sort-Merge join。
Reducer 侧 join 是一种通用的 join 算法,但它有以下缺点:
- Mapper 侧根本不过滤数据,所有数据,即使是那些无法 join 的记录,都会被传输到 Reducer 侧,再由 Reducer 过滤,这样性能很差;
- Reducer 侧可能没有足够的内存装下一个 key 对应的所有记录。
join 优化
考虑这样一个场景:有两个数据集,Customer 和 Order,要求对他们进行 join,但仅限于地区在上海的顾客。
有几种可能的优化方式:
预先过滤一个集合,使用 Replicated Join
利用“地区为上海”这个约束过滤 Customer,如果过滤后的数据集足够小,则可以采用 Replicated Join;
用半连接(semi join)优化 Reduce Join:先过滤集合 A ,再用得到的结果在 Mapper 处过滤集合 B,最后在 Reducer 处 Join
如果过滤后的数据集依然很大,那么只能采用低效率的 Reduce join。优化 Reduce join 的主要策略是 尽量将数据过滤动作放在 Mapper 进行(这也是一个通用准则),在上述例子中, Mapper 在处理某个 Order 时,如果知道其对应的 Customer 不在 Customer 集合中,或者不在上海地区,那么就可以跳过它而不用传输到 Reducer 侧。为了达到这一点,我们可以先对 Customer 过滤(就像1一样),将上海的顾客的* ID *选出来,这样得到的文件比1得到的文件更小(因为它只有一个 ID),很有可能可以被装入内存。用 Distributed Cache 将该 ID 文件分发到所有 Mapper 节点,Mapper 在处理 Customer 或 Order 的记录时就可以根据这个集合过滤所有非上海的顾客了。
如果过滤得到的 ID 文件依然很大,这时判重利器 BloomFilter 就派上用场了。我们可以建立一个 BloomFilter 表示过滤后的顾客 ID 集合,它的尺寸要远小于原始集合。BloomFilter 存在的误判率也不是问题,它只会把不存在的元素误判为存在,Reducer 处也会进行过滤,可以把误判的元素剔除掉。
基于 Mapreduce 为超大集合建立 BloomFilter 的方法:
每个 Mapper 对自己负责的 split 建立 BloomFilter,用一个 Reducer 接收它们并两两相“或”,即得到整体集合的 BloomFilter。
这利用了 BloomFilter 的性质:
filter1 | filter2 == 并集 filter1 & filter2 == 交集
3. 参考
- Mapreduce patterns
- Mapreduce algorithms.pdf
- 《Hadoop in action》
- 《Hadoop 权威指南》