CPU Cache & False Sharing & 存储器层次结构
1. 分层的存储器
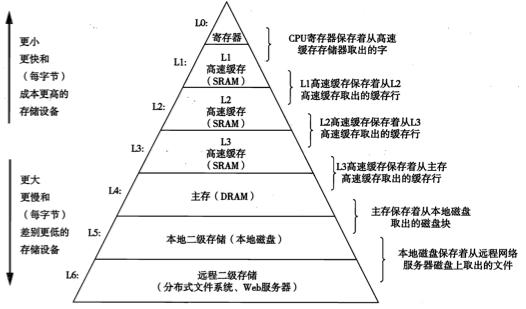
第 k 层是第 k+1 层的 cache, 存储 k+1 层数据的一个子集.
| 访问时间 |
|---|
| 寄存器 |
| 缓存 |
| 内存 |
| 硬盘 |
2. CPU cache
分层,每个CPU有各自的L1/L2缓存,共享的L3缓存。
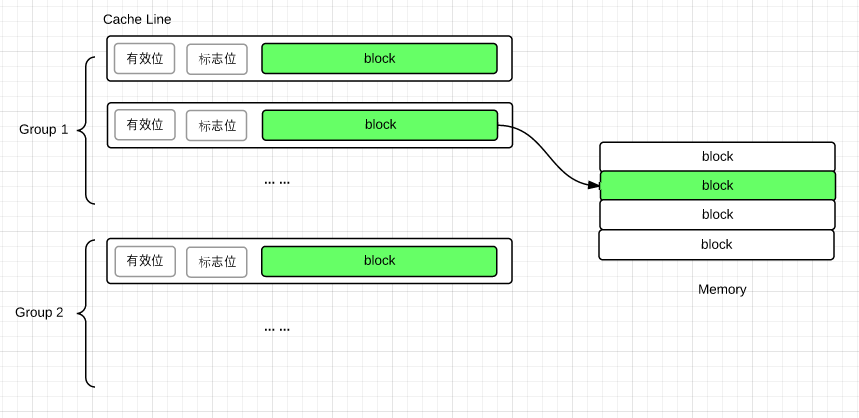
Cache 的基本组成单位是line,cache 和内存交换数据的基本单位称为一个 block,一个line 包含一个 block 和其他信息. 当数据从内存读入时,不会只load一个byte,而是装入整个block, 它通常是32或64字节。
Line和Block这两个术语经常混用, 当出现”Cache Line 的长度是32字节”这种说法时, 很显然指的是 Block.
所有对内存的读/写都要经过 cache。
缓存不命中的种类:
- cold miss, 缓存没数据
- conflict miss, 加载数据到 cache 时, 硬件通常使用严格的放置策略, 而不是随便找一个空位使用, 因为这样的查找效率很低. 因此可能出现不同的数据被映射到同一个 cache line 的情况, 即使还有空间也会出现不命中.
- capacity miss, 缓存空间不够.
cache 的组成结构:
内存地址在逻辑上被划分为这3个部分:
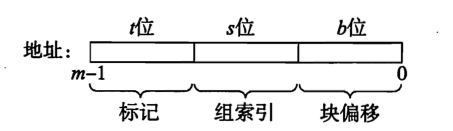
假设 CPU 需要读取某个地址上的一个字, 在 cache 中是这样定位的:
查找 Group
内存地址到 Group 的映射是严格确定的, 即有个 Group, 因此由组索引可直接定位 Group. 这一步很快;
查找 Cache Line
长度为 t 的标记位相当于 Cache Line 在 Gropu 中的序号。对定位到的 Group 中所有的 Cache Line, 将其标志位与内存地址的标记位一一比对, 如果匹配且设置了有效位, 则说明 Line 匹配。 这也意味着填充缓存时可以任意在该 Group 中挑选一个空闲的 Line 存放. 这一步的效率较低;抽取字
根据物理地址中的 块偏移, 在找到的 Line 所存储的 block 中的对应位置抽取字即可.
当每个 Group 只有一个 Cache Line 时, 这样的结构称为直接映射. 此时 cache 的定位跳过了第二步, 但它很容易造成 conflict miss.
当所有的 Cache Line 组成一个 Group 时, 称为全相联. 此时 conflict miss 的概率最低, 可以利用所有 cache 空间, 但缺点是查找很慢, 因此该策略只适用于小规模的缓存.
每个 Group 中有 n 个 Cache Line 时, 称为n 路组相联, 这种结构在 查找速度 和 conflict miss 间做了平衡.
3. 程序的局部性
- 时间局部性 (temporal locality): 一个被引用的内存地址很可能在随后被多次使用;
- 空间局部性 (spatial locality): 如果程序引用了某个地址, 那么程序很有可能在随后引用它附近的地址.
Cache 本身的思想就是利用时间局部性减少热点数据的访问时间 ; Cache 和 内存 之间以 block 为单位交换数据的行为利用了程序的 空间局部性; 现代 CPU 也会根据 空间局部性 prefetch 正在使用的内存地址附近的数据到缓存中. 因此, 编写具有良好局部性的代码的根本目的是为了 提高缓存命中率, 低命中率的缓存不但会增加数据的获取时间, 更会造成频繁的淘汰.
一个常见的提高代码空间局部性的技巧是 始终按数据的存放顺序以步长为1的方式引用数据. 这一点在多维数组的循环时显得更加重要, C 以行优先顺序存储数组, 如果采用一列一列的扫描方式就类似随机访问了, 当数组规模比较大时将显著降低缓存的命中率.
4. MESI协议
TODO
5. False sharing
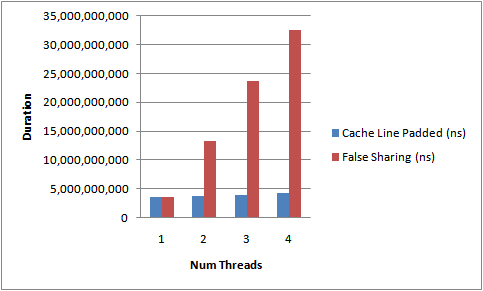
两个变量AB同时存储在一个line中,CPU1需要频繁更新A,CPU2需要频繁访问B(读取或更新),它们在自己的私有 cache 中都拥有该缓存行的一个副本。根据MESI协议,CPU1更新A时需要invalidate其他CPU中的该行,这就造成了CPU2每次访问B都无法命中cache,每次都需从内存载入,大大降低了性能。这种现象称为False sharing。
解决办法是使用 内存padding(即使用额外的变量填充) 增加 A 或 B 的长度, 将它们分散到两个不同的 Cache Line 中.
一个 java 的例子:
对 32位 Hotspot JVM 而言, 每个对象都有 2-word (8 byte) 长度的对象头, 数组有一个额外的 word 保存长度. 对象内部的属性根据内存对齐的要求按照如下顺序重新排列布局:
- doubles (8) and longs (8)
- ints (4) and floats (4)
- shorts (2) and chars (2)
- booleans (1) and bytes (1)
- references (4/8)
- == repeat for sub-class fields ==
因此, 对于通常 64 bytes 长的 cache line 而言, 如果需要两个对象分布在不同的 cache line 中, 只需要在任意一个对象的末尾用 7 个 long (56 bytes) 当做padding 即可.
测试代码:
public final class FalseSharing implements Runnable{
// 思路: 用一个对象数组, 每个元素用一个线程循环改变其内部一个字段的值,
// 分别测试有 padding 和无 padding 的性能
public final static int NUM_THREADS = 4; // 数组元素数量, 亦即线程数
public final static long ITERATIONS = 500L * 1000L * 1000L; // 循环数
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
// 数组初始化
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex){
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++){
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads){
t.start();
}
for (Thread t : threads){
t.join();
}
}
public void run(){
long i = ITERATIONS + 1;
while (0 != --i){
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // <----- padding
// 注意, java 7 会优化掉无用的变量, 需要用一个方法比如 sum使用这些变量
}
}结果对比如下: