Mode Switch 和 Context Switch
1. Mode Switch 和 Exception control flow
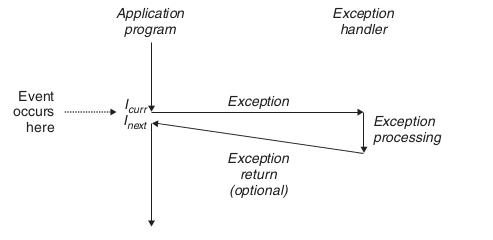
进程通常运行在用户态,只有触发CPU的exception才能进入内核态。此时用户的控制流被挂起,内核接管程序的运行;exception处理完毕后回到用户态,(如果需要的话)在原先的断点处继续执行。
Exception的分类
interrupt,硬件发起,异步(即独立于CPU),下面3种都是同步的(必须由CPU执行某条指令触发)。fault,可能可以恢复,处理后返回引起错误的指令,如Page Fault。abort,无法恢复,不返回。trap / system call,程序主动发起,调用操作系统服务的方式,handler 执行完毕后返回下一条指令。
CPU在处理Exception时,通常是 关中断 的。
System Call 和 普通函数调用 的区别
System Call通过寄存器传递异常号和参数,System Call的处理流程(其他Exception类似):
- 修改CPU的特权模式,进入内核态
- 根据异常号查表(Interrupt Descriptor Table, IDT)找处理程序入口
- 保存现场(如EIP/ESP/通用寄存器等)
- 切换到内核栈
- 执行处理程序
- 恢复现场
- 修改CPU的特权模式,回到用户态
步骤更多(CPU mode切换 / 查表 / 现场的保存和恢复 / 切到内核栈),因此比普通的函数调用开销更大。
System Call 的具体实现
This answer is specific to Linux OS and x86 architecture.
Every system call is identified by a system call number.When a user process invokes a system call it needs to pass the system call number and the arguments to the kernel and get a return value. It does so by copying the system call number and the arguments into the cpu registers(eax, ebx, ecx, edx, esi, and edi) and executing a software interrupt instruction(int $0x80 or sysenter).
The cpu control unit views the software interrupt as any other interrupt. So, a little information on interrupt handling is required. After executing an instruction, the control unit checks for interrupt. The kernel maintains an array of function pointers to the interrupt handlers in an array called interrupt descriptor table(IDT). A cpu register(tr) contains the pointer to information containing the kernel mode stack. Two bits of the cs register specify the privilege mode (kernel mode or user mode).On interrupt, the control unit does the following:
a) Switches the stack if mode switch is required(i.e, the cpu was in user mode). Place the previous stack pointer(esp) and in the new stack.
b) Changes the privilege mode by changing the cs register if mode switch is required.
c) Saves the instruction pointer in the kernel mode stack.
d) Jumps to the interrupt handler by loading the eip register with the function pointer found in theIDT.One entry in the IDT holds a pointer to the function, system_call(). This function does the following:
a) Copies the general purpose registers into the kernel mode stack.
b) Checks the validity of the system call number.
c) Calls the corresponding system call handler. The function pointers to the system call handlers are kept in an array called sys_call_table.
d) Writes the return value of the system call handler in the kernel stack where the value of the eax register in user mode was saved.
e) Executes the iret instruction.The iret instruction does the following:
a) Loads the cpu registers with the values saved in the kernel mode stack.
b) Loads the eip(instruction pointer) and esp(stack pointer) with values saved in the kernel mode stack.
c) Switches to user mode by changing the cs register.Thus, the iret instruction resumes the user process. It gets the return value from the eax register.
2. Context Switch
(以下讨论仅限内核线程,不包括在用户态实现的线程)
CPU切换线程的动作发生在内核态,包括:
- 保存当前线程A context;
- 恢复另一线程B context;
- 执行B
是CPU extensive的。
Context指的是即当前CPU各寄存器的值。
不同进程间线程的切换比同进程内线程的切换代价要高
不同process的切换需要换虚拟内存空间,同一process间thread的切换不需要;
新进程的页很可能被 swap out 了,这时又要把他们 swap in,需要额外的磁盘 IO。Linux(x86) 下其实就是设置寄存器 CR3 的值,因为 MMU 总是从该寄存器中获取页目录的物理地址。
内存空间一切换,大部分 CPU 缓存(除了通常意义上的缓存还包括TLB,Translation Lookaside Buffer,缓存PTE,即 page table entry,为 MMU 加速逻辑地址到物理地址的翻译)将会失效。另外,有些架构下会强制 flush 掉 CPU cache 或 TLB 缓存。
线程和进程的区别
- 线程更轻量,创建/撤销代价小。进程是资源管理的单位;线程是CPU执行的单位;
- 线程共享所在进程的资源,如地址空间/打开的文件。线程的概念试图实现的是,共享一组资源,以便为完成某一任务而共同工作,有时这一点是必须的;
为什么需要线程
提高性能: a) 利用IO阻塞的空闲时间;b) 多核条件下实现并行计算。
什么时候进行 context switch
- System Call / 处理硬件Interrupt的过程中很可能阻塞,这时通常会引发 context switch;
- 时钟硬件 interrupt 通知 cpu 某线程时间片用完,进行切换。
Context switch一般也会进行mode switch;mode switch却不一定会context switch(切换线程),比如简单的系统调用。
Cache Pollution
context switch 和 mode switch(Exception control flow)都会导致cache变cold,这也是二者的开销之一:
- 若exception handler短,则cache对handler而言是冷的;长,返回user mode时cache对用户进程是冷的;
- 线程切换后,原cache对新线程而言是冷的。