消息中心开发过程中踩的几个(常识)坑
碰到的坑主要在数据库并发访问的场景下踩的,原因也比较简单,属于常识坑,这里记录一下,吃一堑长一智。
简单介绍下业务场景,消息中心负责向用户发消息(站内信),比如谁回复了你,谁赞了你,帖子被删被加精,社区又有新活动,上层模块如影评、社区调用消息中心公布的 thrift RPC 接口向用户发消息。
消息分两层:聚合消息(session)和子消息(message),二者是父子关系,message 按照不同的规则合并到 session,比如一个用户收到的帖子回复消息,按各自所属帖子分别聚合到不同 session,所有系统通知聚合成一个 session 等等。
Session和message均有两个文本字段:title和content,为了统一管理各种消息的格式,消息中心预先为每种类型配置了各自的velocity模板,业务方调用时传递参数,消息中心负责模板渲染,生成最终的文本。为了避免MySQL表过大,title和content是保存在Tair中的。
所以当收到一个发布消息的请求时,处理步骤如下:
- 找到message对应的session,如果不存在则创建一个;
- 修改session的发送者、未读消息数、消息总数等字段,渲染得到其title、content,更新之;
- 渲染得到message的title、content,插入之。
1. if (not exist) INSERT else UPDATE
第一步的实现一开始是这样的:
session = findSession(msg);
if(session == null){
session = new Session();
// 更新session字段
add(session);
}else{
// 更新session字段
update(session);
}这样的实现有两个问题:
- add(session)时可能已经有其他事务insert成功了,此时再add会失败;
- 高并发时,insert同一条数据比较容易产生死锁,这个问题足够再写篇笔记了,不赘述。
对于问题1,数据库并不会出现脏数据,只是会在代码层面抛出异常,导致业务方发布消息失败。通常发消息的动作会是一个异步调用,调用方通常可以接受等待,但不能忍受异常失败,更不愿意捕获异常进行重试,因为相对的发消息只是一个支线流程,复杂度不宜太高。
MySQL 提供了对标准insert语句的扩展 INSERT INTO ... ON DUPLICATE KEY UPDATE ...,如果 insert 触发了索引重复异常,则转为执行 update 动作,非常适合这里 “如果不存在则insert,存在则update” 的场景。重申,这是一个API的设计问题。
对于问题2,ON DUPLICATE KEY UPDATE依然无法避免死锁(见MySQL bug 52020,死锁现场见该条gist),但概率会低一些(无责任嘴炮中…)
经验教训:
- 用
INSERT INTO ... ON DUPLICATE KEY UPDATE ...代替代码中if null INSERT else UPDATE的逻辑。
2. 自增字段的第二类丢失更新
session 中维护了未读消息数(unreadCount)、消息总数(totalMsgCount),来了一条新消息必须自增这两个字段。最早的版本是在代码里先读这俩字段,+1再用update(session)写回DB,update是一个全字段的更新动作,但这显然有所谓的“第二类丢失更新”的问题。
第二类丢失更新问题指的是两个并发的update动作,后提交的(假设B)将先提交的值(假设A)覆盖掉。如果A是一个普通的update倒也没什么问题,但如果A的逻辑是在代码里做自增/自减,然后再更新,那么A的自增/自减就会被覆盖掉:
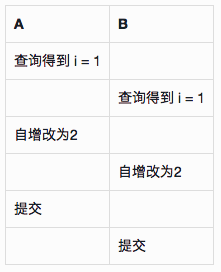
解决办法是在DB层面用UPDATE语句做自增自减,利用DB的锁机制保证更新动作的互斥。但这还不够,代码里经常有这样的逻辑:先读一个对象,修改某些字段,再用update(obj)类似的语句更新到DB。如果update(obj)是全量更新,那么仍然存在问题:
- A 将字段i自增1;
- B 读该对象,修改非i的字段;
- A 提交;
- B update(obj) 并提交事务,A 的自增被覆盖了。
所以最后的解决方案是:
- 对每个需要自增自减的字段在DAO层提供
incr(incBy)方法,通过UPDATE语句自增自减; - 将自增自减字段从各种
UPDATE语句中移除,通过1提供的方法单独维护。
3. 锁超时
消息中心上线后,PM提出要将原有社区的消息全部迁移到消息中心,当时用了一个数量为24的线程池并发做数据迁移,结果测试时后台JDBC不停地报INSERT INTO ... ON DUPLICATE KEY UPDATE socket超时,而这句SQL是整个事务调用的第一条语句。
一开始怀疑是网络问题,于是把JDBC连接字符串中的socketTimeout参数调高到10s,然而并没有什么卵用。考虑到只有在数据迁移这样的并发场景下才会出现问题,很自然地想到会不会是锁超时。回顾发布消息的流程,第一步是更新消息所属Session,如果测试数据中有一批连续的消息发送给同一个人,且对应的聚合消息为同一条,那么极端情况下会出现24个线程争用同一把锁的情况。
但即使如此,如果每个事务的时间都比较短,对最后一个获取锁的事务而言10s也应该够了,除非事务里做了什么耗时的动作。按这个思路用 spring 提供的 StopWatch 分别对数据库操作、模板渲染&保存到Tair两个阶段计时,发现前者平均30ms,后者则高达300ms,问题应该就出在这里。
修复方法很简单:
- 降低线程数量,24–>12;
- 将模板渲染 & Tair存取的动作提到事务外面,降低事务耗时。
但这样一来我们就无法利用事务的原子性了,假如模板渲染或Tair失败,事务并不会回滚,用户会看到title或content为空的消息。考虑到真实业务中并不会出现同时给一个人发送大量消息的场景,相对并发程度而言,线上的数据完整性更重要,因此只在数据迁移时用了上面的方案。假如哪天既要保证并发度,又要保证数据完整性,可以使用上述方案,并在第二步失败时手动对数据订正,将脏数据还原或删除;用户在一个极短的时间窗口内是可能看到脏数据的,但这并没有太大影响。
最后还有一个问题,明明是锁的问题,为啥报 socket 超时呢?这是因为 InnoDB 锁超时时间由参数 innodb_lock_wait_timeout决定,默认值为50s,测试数据库并没有修改,因此 JDBC 只会发现 socket 读超时,而无法感知到锁超时。
经验&教训:
- 耗时的动作不在事务里做,尽量减少锁的持有时间;
- 根据具体业务的特点和需求,在事务的ACID与并发性之间做tradeoff,必要情况下可以允许短暂的脏数据,事后再进行数据订正;
- 活用 spring / apache.commons 提供的
StopWatch分析任务耗时。