C及虚拟内存总结
1. 数据类型
1.1 整数
// 32位下:char // 1 byteshort (int) // 2 byte,int可以省略int // 4 byte,int可以省略long (int) // 4 bytelong long (int) // 8 byte
// 每个类型都分为有符号/无符号两种
// 字面量的后缀:// U: unsigned, L: long, LL: long long, 可以混合用1.2 浮点数
// 32位下:float // 4 bytedouble // 8 bytelong double // 10 byte
// 字面量后缀:// 默认是double, F: float, L: long double1.3 enum
enum color { black, red = 5, green, yellow };
enum color b = black; // 0enum color r = red; // 5enum color g = green; // 6enum color y = yellow; // 71.4 字符常量
'A'默认是int型,sizeof('A') == 4.
1.4 字符串常量
- 字符串是以
NUL(也就是\0) 结尾的char数组。 strlen不计算NUL,sizeof计算字节数(包括结尾的NUL)。char s1[] = "abc";VSchar* s2 = "abc";:
前者是char s1[] = {'a','b','c'}的快捷方式, 定义了一个字符数组,其内容可以修改;后者定义了一个内容为abc的字符串常量,该常量运行时存储在 data段的read-only区 ,无法修改,s2指向其第一个元素。
2. 类型转换
2.1 寻常算术转换
当操作符两端的操作数类型不一致时,按以下顺序做类型转换:
long double > double > float > unsigned long > long > unsigned int > int
低级别自动转换到高级别。
unsigned int 和 int 比较时,由于算术转换产生的BUG:
int array[] = {1,2};#define LENGTH (sizeof(array) / sizeof(array[0]))...if(-1 <LENGTH) // 返回false!...这是因为sizeof返回的值是unsigned int类型的,与-1这个int比较时,-1先转型为unsigned int,结果是一个巨大的整数。
所以,尽量不要使用
unsigned。当混合使用时,在表达式中应该使用强制类型转换,使操作数均为有符号或无符号的。
2.2 整型提升
上述列表覆盖了所有浮点数类型和部分整型,当操作数的类型为列表之外的短整型,如char/short时,即使两端的操作数类型一致,编译器也会先将操作数提升到int,运算后的结果也是int。这种隐式的转换称为整型提升。
因此:
char a = 'A';char b = 'B';printf("%d",sizeof(a-b)); // 将打印4函数调用时参数的整型提升
函数调用时,形参和实参的传值和普通赋值一样,因此也会出现整型提升的情况。比如参数为short/char时,实际压入栈中的是int类型,函数内部再进行隐式的裁剪。
这就是为什么printf()中的%d可以适用几个不同的类型(int short char)。函数内部在处理%d时,总是按int长度从栈中取参数(可以用%d打印一个long long整数验证下),刚好整型提升保证了这个行为的正确性。
3. 运算符
3.1 sizeof
sizeof是个运算符,返回操作数的字节数。返回值是size_t类型,操作数可以是类型和变量,后者可以不用括号。
3.2 重要的运算符优先级
指针相关:
a. 后置运算符如 数组[] 函数() 的优先级 > 指针*
| 错误 | 正确 |
|---|---|
int *ap[] |
指向数组的指针,同int (*ap)[] |
int *ap() |
指向函数的指针,该函数返回int |
b. . > 指针*
| 错误 | 正确 |
|---|---|
*p.f |
(*p).f |
c. ++ -- > 指针* > 加减运算符 +-
| 错误 | 正确 |
|---|---|
*p++ |
(*p)++ |
*p+1 |
*(p+1) |
d. == != > 赋值 =
错误方式: c = getchar() != EOF
正确方式: (c = getchar()) != EOF
e. && > ||
3.3 结合律
规定当几个操作符有相同优先级时,先执行哪一个。
常见的都是从左到右,赋值运算符(= += -= ...)的结合律是从右向左,a=b=c,先执行b=c
3.4 计算的次序
大部分表达式中,操作数的执行次数是不确定的,如 x = f() + g() * h(),f/g/h三者的执行顺序是不确定的;
函数调用时,参数的计算次序也是不确定的;
但是,&&和||是短路求值的,即从左到右计算,得到结果即停止。
4. 语句
4.1 do...while(0) 的作用
类似其他高级语言的try...catch异常机制。
do{ // 前置条件的检查 if(firstCheckFail()) break; if(secondCheckFail()) break;
// 检查通过,正式开始业务逻辑。
}while(0);5 声明
5.1 阅读复杂声明的方法
取最左边的标识符,由最内的括号开始往外一层层考察,考察时先往右后往左:
向右:
[]:”含有…的 数组”(): “返回…的 函数”
先考察右侧的这两个符号是因为他们的优先级比*高。
向左(从右向左阅读):
*: “指向…的 指针”const/volatile:- 类型信息
5.2 声明和定义 (declare & define)
声明:指代其他地方定义的对象,向编译器提供一个符号的信息(如变量的类型/函数的参数返回值),使后面使用该符号的地方不会出错。
使用extern关键字进行声明:
- 声明一个 变量:
extern int i;,没有extern关键字则成为定义 - 声明一个 函数:
extern int fn(int);,即函数原型,参数名可以不 - 写,
extern关键字也可以省略。没有参数时要用void,否则会被解释成任意多的参数。
定义:为对象分配内存。
- 变量
定义在函数之外的,是 全局 的。
定义在函数之内的,是局部变量,分配在栈上,有一个关键字auto用来修饰这种类型,但一般不会使用。
static变量和全局变量类似,除了它只在当前文件中可见。
register关键字让编译器尽可能将该变量存储在寄存器中。 - 函数
定义函数时要提供函数体。
函数默认是全局的,有一个冗余的修饰符extern,但一般不会用。
static也可以修饰函数,表示该函数仅在当前文件中可见。
inline内联,向编译器建议需要更快地执行该函数,这通常是通过将该函数的代码提升到调用者内部实现的,省去了函数调用的开销,但会造成调用者的函数体变大。
inline函数和#define的区别:
#define工作在 预处理阶段 仅做简单的文本替换。inline工作在 编译阶段,从语义上讲和调用一个普通函数的效果是一样的,也会对参数做检查和转型,因此更安全。
可以有多个声明,但只能有一个定义。
5.3 const
`const`并不能把变量变成常量,它只是说明 **这个符号不能被赋值**,即它的值对于这个符号而言是只读的,可以通过别的途径修改,比如通过一个指针。 `const`和指针连用:int const * a;const int * b;int * const c;- a和b中的
const是修饰int的,ab是一个指针,指向const int,自己可以修改,但指向的内容不能修改 - c中,
const是修饰*的,c是一个const指针,指向int,自己不能修改,指向的内容可以修改。
5.4 typedef
`typedef`的语法和**声明一个变量**是一样的,但它的作用是为某个类型赋一个别名。typedef struct{int a,int b} pair; // structtypedef int array[5]; // 数组typedef int (*fn)(char); // 函数指针5.5 .h 和 .c,interface 和 implementation
一个模块通常由`interface`和`implementation`两部分组成,前者声明了模块对外提供的服务,包括对外公开的函数和变量,后者是对前者的实现,客户端仅依赖`interface`而不关心具体实现。
在C中,`interface`的角色是由`.h`文件担任的,其中通常包括了:
- 对模块公开变量(即全局变量)的声明;
- 对模块公开方法的声明;
struct/union/enum类型声明;#define/typedef
客户端通过include.h文件使用该模块提供的服务。
在.c文件中,static类似java中的private关键字,不需要暴露给外部的函数/变量都应该定义为static的。.cinclude该模块的.h文件,编译器可以保证二者的一致性。
为了防止重复include,.h文件中的include guard
// 开头:#ifndef MODULE_A#define MODULE_A
// 其他内容
// 结尾:#endif6. 函数
6.1 调用
6.1.1 传值调用
所有的调用都是传值调用。
6.1.2 stdcall vs cdecl
不同的编译器对函数调用有不同的实现,一般有两种方式:
stdcall
调用者负责参数入栈,被调用者在结束时负责参数出栈,只能根据自己的参数列表出栈,因此 无法实现可变参数。cdecl (默认)
调用者负责参数的入栈和出栈,调用者是知道参数长度的,因此 可以实现可变参数。
二者参数入栈的顺序都是 从右到左。
6.2 不定参数的函数
不定参数列表只能放在参数的最后面:
int sum(int n, ...){}基本的工作原理是用一个指针,初始指向栈中 最后一个确定参数的结束地址 ,按给定的数据类型,依次读取对应长度的字节,并移动该指针。
函数内部无法知道可变参数列表的长度,因此需要显式告知:
- 将长度作为函数参数;
- 用一个约定的值表示参数结束,类似字符串字面两结尾的
NUL.
需要依赖的几个宏:
#include <stdarg.h>
va_list ptr; // 移动并读取可变参数的指针va_start(ptr, 最后一个确定参数) // 用最后一个确定参数初始化ptrva_arg(ptr, 参数类型) // 按指定类型读取一个可变参数,并移动ptrva_end(ptr) // 使ptr无效
/*使用模式*/void foo( int bar, ... ) { va_list ptr; // 1 va_start(ptr, bar ); // 2
for (未读取完参数) { some_type arg = va_arg(ptr, some_type ); // 3 /* Do something with arg */ } va_end(ptr); // 4}
// 参考:以上宏x86上的一种实现typedef char *va_list;#define va_start( ptr, param ) (ptr = (va_list)(¶m + sizeof( param ))) // 让ptr指向param的结束地址#define va_arg( ptr, type ) (*(type *)((ptr += sizeof( type )) - sizeof( type )) // 按type读取ptr指向的值并移动ptr#define va_end(ptr) ( ptr = (va_list)0 ) // 使ptr无效6.3 函数指针
注意,函数名是指向该函数的指针
typedef void (*FuncPtr)(); // 声明了一个函数指针类型
void foo(){} // 函数名foo是个函数指针
FuncPtr bar = foo; // 或:void (*bar)() = foo(*bar)();bar(); // 直接通过函数指针也可以调用7. 指针
一个指针有两个属性:
- 指向的 内存地址;
- 指向的 类型。
void* 指针: “万能指针”,只知道地址,不知道类型,必须转型成其他类型的指针才能使用。
指针的运算:
- 和整数加减: 以该指针指向的类型为单位,偏移指针;
- 指针之间相减: 获得两个元素在数组间相隔多少个元素;
- 指针大小比较: 判断两个元素在数组间的相对位置。
- 取下标
p[i]: 效果和*(p+i)相同,就是偏移指针
8. 数组
8.1 数组和指针
- 在所有表达式中,数组名是一个指针字面量,它的值是数组第一个元素的地址,可以认为是
指向数组第一个元素的指针。以下情况例外:
sizeof(数组名):返回整个数组的字节长度;&数组名: 返回一个指向数组的指针,它的地址和数组内第一个元素的地址相同,但其指向的类型是一个数组,而不是元素的类型,这是指向数组的指针和指向数组第一个元素的指针(数组名)唯一的区别。
注意,数组名是个指针字面量,因此:
- 无法对数组名重新赋值,因为它是个字面量;
- 用
p[i]对指针偏移,p为数组名和指针时是有区别的:
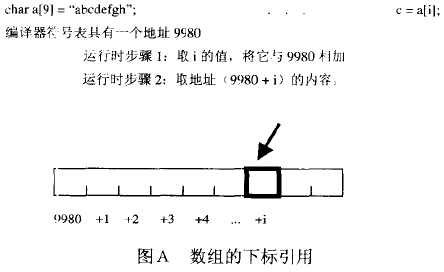
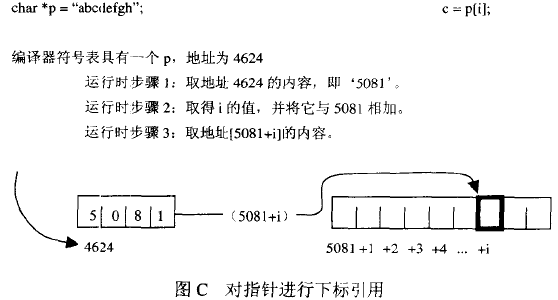
当 定义为数组,但声明为指针使用 时的错误:
// file a.cchar p[10]; // 假设编译时确定p的地址是776
// file b.cextern char *p;char a = p[2];/*将p当作指针做偏移,步骤如下:1. 到地址776,取其内容; <-- 实际得到的是p的第一个元素,一个char2. 进行偏移; <-- 在一个char上进行指针运算,显然是错误的。3. 访问2得到的地址*/
- 若函数的参数声明为数组,内部得到的实际上是一个指向数组第一个元素的指针变量。
- 因此对数组形式的参数,
sizeof()返回的是指针长度(即机器字长),也可以对其赋值; - 声明函数时,参数可以用数组形式,也可以用指针形式:
void func(int *p){} // 更精确
void func(int a[]){} // 长度可以省略,因为函数内部不知道数组长度
void func(int a[200]){}
- 对以上形参,可以用
指针/数组名调用。所有属于实参的数组,都会被编译器改写成指针:
int array[10] = {..};
int *p = ...;
func(array); // 传递数组
func(array + 2); // 传递数组的一部分
func(p); // 传递一个指针
8.2 初始化
int a[5] = {1,2,3}; // 给定长度和不完整的初始化列表,剩下的元素被初始化为0int a[] = {1,2,3}; // 有初始化列表,可以省略数组长度// 字符数组:char a[10] = "abc"; // 一个长度为10的char数组// 不是定义一个数组,而是定义指向字符串常量的指针char *b = "abc"; char c[] = "abc"; // 同上8.3 二维数组
- 数组的数组;
int a[2][3]的内存布局:^^^|^^^;a是指向数组第一个元素的指针,即一个指向长度为3的数组的指针(类型是int (*a)[3]),它指向的地址和&a[0][0]相同,不同的是指向的类型。对它+1将指向下一个子数组;*(*(a+1) + 1)和a[1][1]一样;
8.3.1 二维数组的初始化
int m[2][3] = {1,2,3,4,5,6}; // 初始化列表坍缩为一维int m[][3] = { // 第一维可以自动计算 {1,2,3}, {4,5,6}};char const s[][9] = { // char型二维数组,15*9,空的位置填0 "string1", "another string"};8.3.2 指向数组的指针
int a[10] = ...; // a是一个指向a第一个元素的指针int (*p)[10] = &a; // p是一个指向数组a的指针a == p; // TRUE,即a和p指向的地址是一样的,不一样的只是指向的类型*p; // 数组a*a; // a[0]8.3.3 指针数组
常用于锯齿状二维数组,数组的每个元素是一个指针,常用于字符串数组。
char *words[] = { // 每个指针都指向一个字符串常量 "first", "second", NULL}8.3.4 二维数组作为函数参数
// 一维: 二维(按数组的数组方式理解):void func(int *p) void func(int (*p)[10]); // 指向子数组的指针// 除了第一维,后面的维度都不能省略。因为需要知道内部元素(即子数组)具体的类型。void func(int a[]) void func(int p[][10]) void func(int a[200]) void func(int p[2][10])9. struct
struct Foo{ int a; char b; float c;};struct Foo bar = { // 初始化 1, 'c', 3.14};bar.a; // 直接访问struct Foo *p = &bar;bar->a; //间接访问
// typedef struct:typedef struct{...} Foo;Foo bar;9.1 内存补齐
参考:《Structure Member Alignment, Padding and Data Packing》
一个变量对起始内存地址有要求,默认条件下,n byte的类型是 n byte对齐 的,即:
- 变量的
起始地址必须要被n整除
- 变量的
结束地址必须要被n整除(主要针对struct)
原因:为了CPU能用最少的时钟周期读取一个变量。
举个例子,在一个字长32bit的机器上,CPU通过总线一次性可以读取4个字节,为了效率,内存按照字长被依次分组,每一组称为一个bank,CPU对内存的读取是以这些bank为单位的。如果一个4个byte的int跨越了两个bank,则需要读两次;当起始地址刚好是4的倍数时,一个int刚好占一个bank,CPU只需读一次。
假设有以下全局变量(32位平台):
/*典型32位下的类型长度:char 1 byteshort 2 bytesint/long/float 4 bytesdouble 8 bytes*/char *p;char c;int x;p是4字节对齐,c是1字节对齐,x是4字节对齐。因此按照规则:
- p开始的地址必然是4的倍数;
- p和c之间不需要补齐,因为
char可以从任意地址开始存放; - c和x之间需要3字节补齐
如果p和c的位置换一下:
char c;char *p;int x;现在c和p之间需要补齐,但具体长度不能确定,因为无法确定c是在bank中的哪个位置存放。
再看看struct:
- 第一个成员的起始地址就是
struct的起始地址,即开头是没有空隙的; - 内部的变量均得满足自身的对齐规则;
- *
struct类型自身必须按照其内部最长的成员变量进行对齐 *。即假如内部最长的成员是4个byte长,则该struct类型是4 byte对齐的。
举个例子:
struct foo{ char a; int b; short c;}内部最长成员是int4个字节,因此struct foo是4 byte对齐的。
- 按照规则1,a的起始位置肯定是4的倍数(一个
bank的开始); - b是
4 byte对齐,a和b之间需要长度为3的padding; - bc之间不需要padding;
- * 按照规则2,c后面需要长度为2的padding,这样结束地址才能被4整除 *。
这是为了当声明一个struct数组时,每个元素的起始地址都满足对齐条件(n+1的起始地址是n的结束地址)。
减少padding:
按长度顺序声明
struct的member
查看struct中member的偏移量:
#include <stddef.h>... offsetof(struct foo,b) ...修改默认的对齐策略:
#pragma pack(push) //保存对齐状态#pragma pack(1)//设定为1字节对齐,其实就是不要对齐struct test{ char m1; double m4; int m3;};#pragma pack(pop)//恢复对齐状态10. 编译/链接/装载
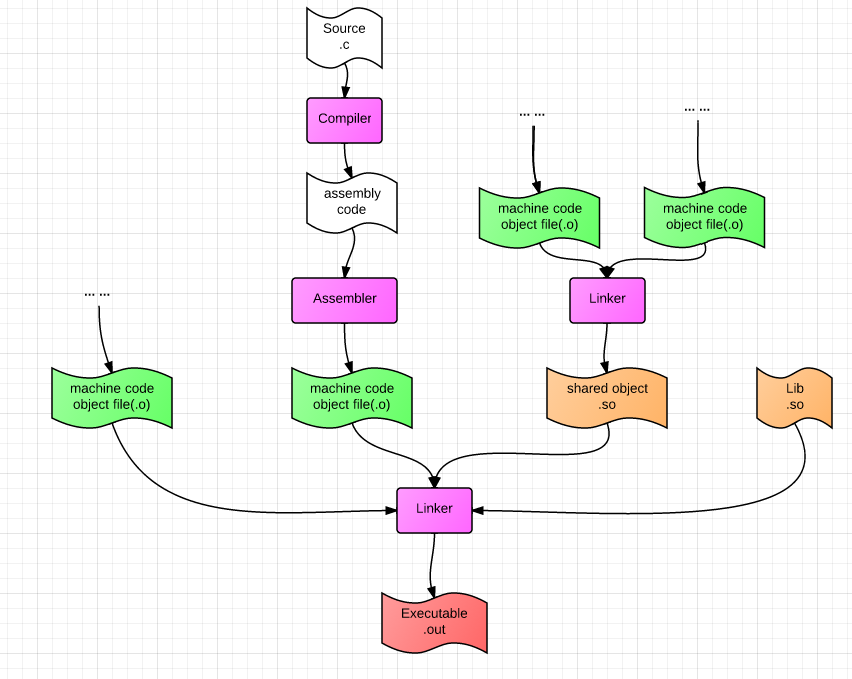
动态链接的优点:
- 减小可执行文件的体积大小;
- 所有链接了某个动态库的可执行文件,在运行时共享该共享库在物理内存中的同一份拷贝,节约内存开销。
装载可执行文件/动态库基本上都是依赖mmap()系统调用进行的,当多个进程映射了同一个共享库,它在物理内存中的开销却只有一份。
mmap()
该系统调用将磁盘上的文件映射到虚拟内存,对文件的读写就像访问普通内存,物理内存作为二者之间的cache。mmap()的一个重要特性是,当多个进程映射了同一个文件,其所占用的物理内存可以被共享,这一特性通常用来实现名为共享内存的进程间通信。
用gcc创建动态库/链接动态库生成可执行文件,见《Shared libraries with GCC on Linux》。
11. 运行时结构
11.1 段
目标文件/可执行文件遵循ELF格式,主要由3个段组成:- 文本段
text
存储代码; - 数据段
data
有初始值的全局变量和static变量,包括他们的初始值;
字符串常量。 BSS
没有初始化的全局变量和static变量,只记录这些变量需要的空间大小。
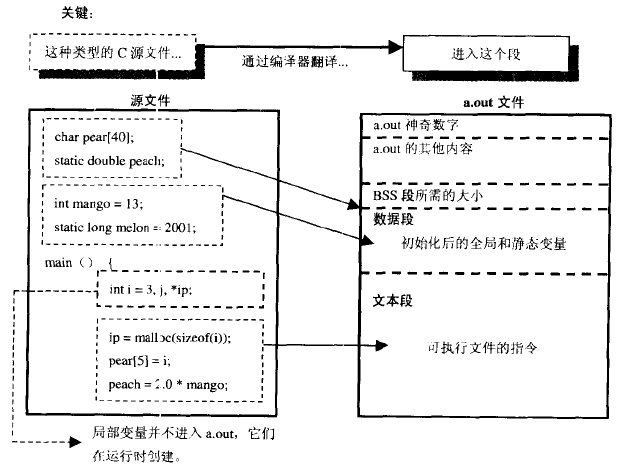
11.2 运行时内存结构
程序运行时,装载器简单地使用mmap()将可执行文件中的各个段映射到虚拟内存中:
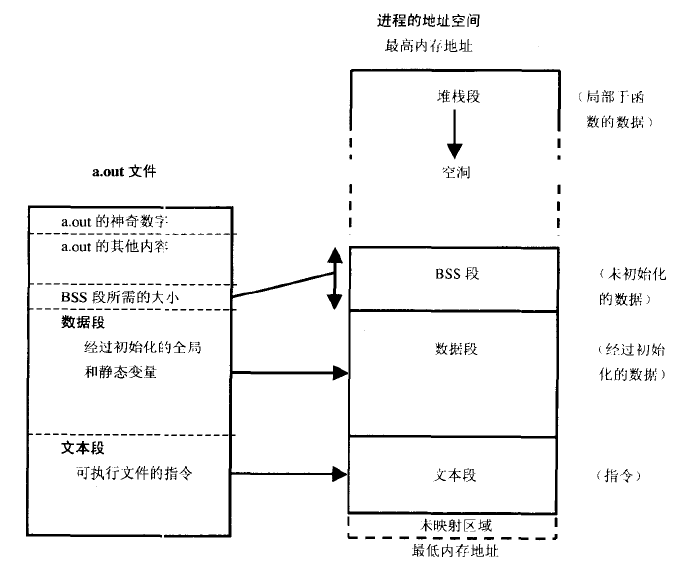
虚拟地址空间的不同段,或者段的不同部分会被设置不同的权限,如text段一般是可读可执行的;data中存储全局/静态变量的部分是可读可写的,存储字符串常量的部分是只读的。
BSS段会被初始化为0。
BBS上方是堆,用于运行时动态分配内存,向上增长;栈 用于函数的执行,它是从高地址向低地址增长的,每个线程有自己的栈,初始大小为1M,按需要增长。
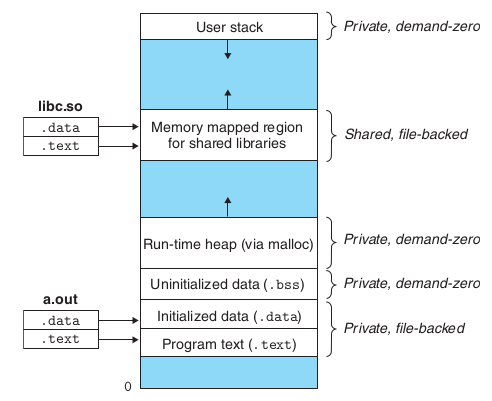
此外,虚拟地址空间还需要分配一部分映射到共享库文件(mmap),将共享库考虑在内进程的地址空间如下(省略了内核空间):
11.3 函数调用和栈
栈的基本单位是stack frame,frame的入栈出栈实现了函数的调用和返回。此外,栈主要为函数运行时提供必要的数据,如:
- 函数的局部变量;
- 参数;
- 保存返回地址,被调用函数返回后可以继续执行;
- 保存寄存器,防止被调用函数污染;
- 等等。
两个栈相关的寄存器:
ebp (base pointer)
始终指向当前frame的底部,在当前函数运行的过程中不会更改。局部变量和函数参数一般都是通过它加上偏移量访问的;esp (stack pointer)
指向当前frame的顶部,随程序运行不停伸缩。
cdecl方式的函数调用过程如下(参考):
| 调用者frame | 被调用者frame |
|---|---|
| 1 | 参数依次入栈,顺序从右到左 |
| 2 | 保存部分寄存器 |
| 3 | call 被调用函数地址: 1. 返回地址(即eip,第12步指令的地址)入栈;2. eip = 被调用函数地址,流程进入被调用函数 |
| 4 | push %ebp:保存父frame的ebp以便恢复 |
| 5 | ebp = esp: 将ebp指向子frame的底部。由上一步可知,此时frame底部保存着父frame的ebp。 |
| 6 | 保存部分寄存器 |
| 7 | 为局部变量分配内存 |
| 8 | …代码逻辑中… |
| 9 | 恢复部分寄存器 |
| 10 | leave, 恢复ebp和esp到调用前(第3步)父frame中的状态: 1.esp = ebp - 4; 2. ebp = *ebp。注意,此时esp指向的内存中保存着函数的返回地址。 |
| 11 | ret:将返回地址出栈,并设置给eip。流程回到调用者。 |
| 12 | 恢复部分寄存器 |
| 13 | 参数出栈 |
可以看到:
- (
cdecl约定下)参数是保存在父frame中的,由父frame传递和清除。这也是为什么cdecl调用方式支持可变长参数; - 寄存器在进入调用和退出调用时要保存和恢复。被分为两类,一类由调用者在父frame中维护,一类由被调用者在子frame中维护;
- 子函数的退出主要是两点:1. 恢复
esp eip两个寄存器到进入调用时的状态;2. 跳转到之前保存的返回地址。
不要在函数中返回指向栈内分配的内存的指针,如:
char* fn(){ char p[2] = {...}; return p;}函数退出后,数组就会被撤销,p指向的内存是未定义的。
12. 虚拟内存
虚拟内存(Virtual Memory, VM)是对硬件(物理内存/磁盘扩展)的抽象,它主要有两个优点:
- 为所有进程提供一个连续的/统一的/互相隔离的虚拟内存空间;
- 将磁盘作为物理内存的扩展,突破物理内存的限制。
12.1 基本思路
用磁盘扩充物理内存,这一部分磁盘空间被称为swap空间,它和物理内存一起组成实际可用的内存;物理内存用于存放最近需要的热点数据,当物理内存中的数据有一段时间未被使用,它就可能被淘汰,移入swap,空出来的空间用于载入需要使用的其他数据。这个数据交换过程类似cache。
每个程序在运行时看到的都是自己私有的虚拟地址空间,在32位机器下是一块从0到4G的连续空间。CPU中的MMU(内存管理单元)负责截获CPU发出的内存访问(虚拟地址),将其翻译成实际的物理地址。当访问的内存不在物理内存中而在swap时,MMU将触发page fault,内核负责将数据从磁盘载入到物理内存,如果物理内存已满,内核还会依据一定的淘汰算法将某些冷数据移动到swap以腾出空间,整个过程对CPU和进程而言是透明的。
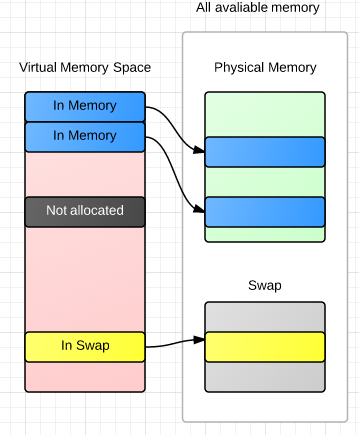
虚拟内存被划分成若干page,一个典型的page是4k大小,它是虚拟内存/物理内存间映射的基本单位,也是物理内存和swap数据交换(page in/out)的基本单位。虚拟内存中的page只可能有3种状态:
- 未分配: 不占用任何物理内存或磁盘上的空间。
- 已分配
- 映射到物理内存
- 映射到swap
12.2 Page Table
虚拟内存和物理内存/SWAP间page的映射关系保存在一张常驻内存的表中,该表由操作系统维护,称为Page Table,MMU在翻译虚拟地址时需要查询该表。每个进程有自己的Page Table,其结构基本如下:
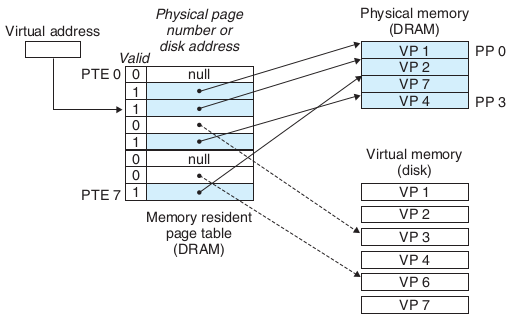
虚拟内存中的每个page在表中对应一个记录,第一个bit表明该页是否在内存中,若在内存中,address字段存储该页在物理内存中的起始地址;若不在内存中,当address字段如果不为空时,存储的是该页在swap中的起始地址,否则说明未分配。
多级Page Table
假设在32位系统中,每页4k,则页表需要1M个记录,假设每个记录4byte,每个进程的页表占用4M物理空间,且是常驻内存的,这是不可接受的。
Linux对页做了进一步的分级。原先地址的前20位表示页的序号,后12位是页内的偏移;现在将前20位划分为两部分,前10位表示目录(directory),后10位表示目录内的页号,如下所示:
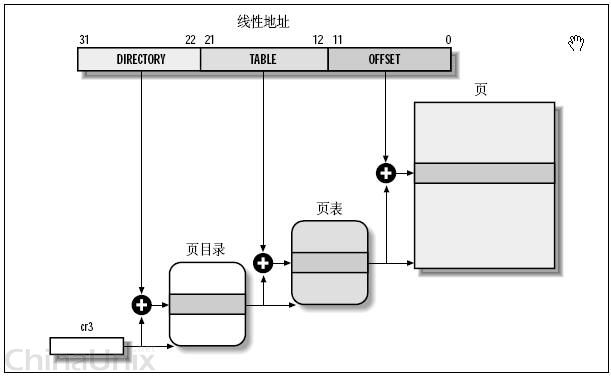
这种分级的方式可以节约内存,因为:
- 如果某个目录内没有分配页,那该目录就不需要一个页表。在实际应用中,一个进程的大部分内存空间都是未分配的,因此可以节约大量空间;
- 只有目录表才需要常驻物理内存,页表和其他普通的页一样,可以被换入换出,只有最经常使用的二级页表才被缓存在物理主存中。 ——不过Linux并没有完全享受这种福利,它的目录表和页表都是常驻内存的。
12.3 Page Fault
当MMU在查询Page Table后发现某一页不在物理内存中,将触发Page Fault,按照标准的错误处理机制,OS将切换到内核态执行对应的处理程序,Linux下的逻辑为:
- 如果该页未分配,触发
segment fault异常并退出; - 已分配但权限错误(如访问内核态内存空间/对只读区段写),触发
protection exception退出; - 否则说明该页在SWAP中,内核负责将其移入物理内存。如果物理内存已满,某个page被淘汰至SWAP以腾出空间。处理程序退出后,重新运行引发
Page Fault的指令。
12.4 Page的分配
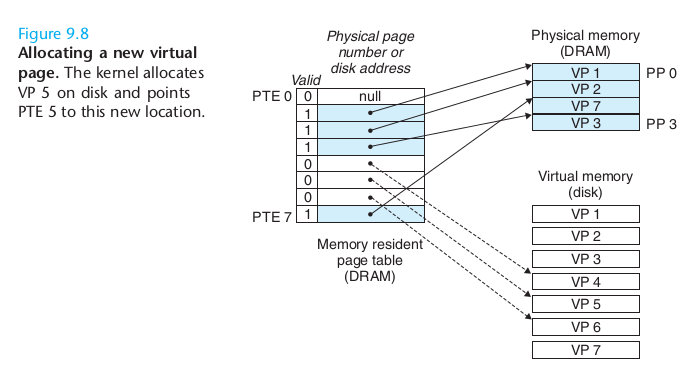
当为进程分配虚拟内存(如通过malloc)时,对一个新分配的页,首先会在SWAP上分配一个页(也可以指定映射到一个文件,或内核创建的一个虚拟匿名文件,后续mmap会提到),然后更新该页在页面中的记录,并建立二者的映射。因此,虚拟内存中的page刚刚分配时是不占用物理内存的,直到第一次使用时被内核换入,才真正消耗了物理内存。
12.5 Linux进程的虚拟内存布局:
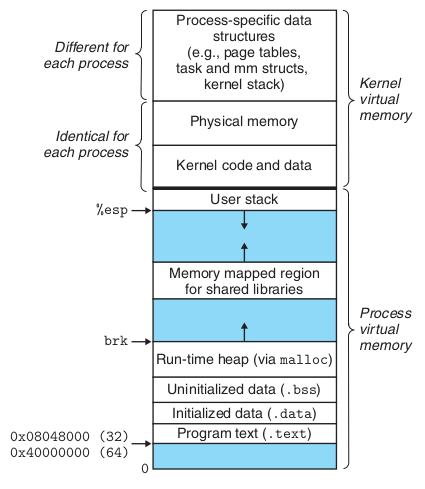
虚拟内存被分为了两个部分,下半部分为用户空间,上半部分为内核空间,32位系统中前者3G,后者1G。
内核空间保存着内核所需的代码和数据结构。某些部分所映射的物理页是所有进程共享的,如内核代码和某些全局数据结构;此外,一块连续的虚拟内存空间与系统所有可用物理内存相映射,这是为了方便内核访问任意地址的物理内存。
内核空间的其他部分存放进程特有的数据,如页表 / 内核栈(如执行系统调用时使用) / 其他进程元数据。
12.6 Memory Mapping和mmap系统调用
mmap系统调用可以分配一块虚拟内存,并将其和磁盘上的某个文件关联起来:
文件系统中的文件
映射也是以page为单位的,根据虚拟内存的SWAP机制,这些page在第一次访问时才会从映射文件换入物理内存,否则是不占内存的。内核创建的匿名文件
当第一次访问某页时,内核将为其在物理内存中分配空间(初始化为0)并建立映射,效果就是为进程分配了一块虚拟内存。
一旦建立了文件映射,分配的page同样会在物理内存和SWAP间page in/out,和其他的普通page并无区别。
mmap一个重要的特性是可以指定共享模式(shared/private)。假设两个进程映射了同一个文件,如果是shared模式,他们使用的物理内存是共享的,此时任一进程对该区域的修改对其他进程是即时可见的。
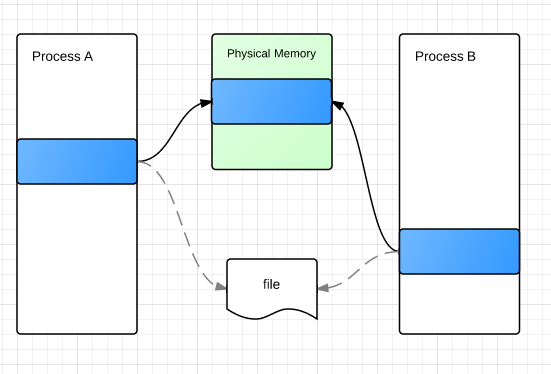
如果指定了private,各进程之间对映射区域的修改互不可见。操作系统为了节约内存使用了copy-on-write方式:假设AB以private方式映射了同一个文件,初始他们使用的物理内存是共享的,和上图一样,但其权限设置为read-only。当A写时将触发page fault,内核在错误处理程序中将为A复制该page,并修改A的page table中的映射关系,这种惰性部分复制的方式有效减少了内存的开销:
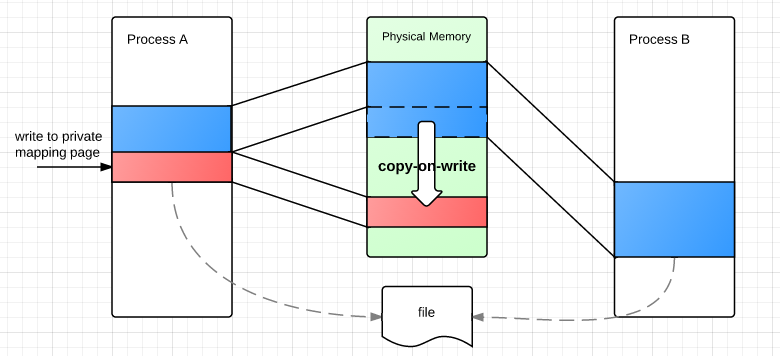
常见用途:
1: 装载/动态库
装载器载入可执行文件/ 动态连接库的映射都是通过mmap方式实现的。得益于shared模式,同一可执行文件上的不同进程可以共享text段/data段中read-only区的物理内存;依赖同一个库的不同进程也只需一份内存开销。
当很多进程都对同一个文件读时,mmap可以节省大量内存。
2:更快更方便地读写文件
更快:
- 每次
read/write都是一次系统调用,mmap方式只需要一次系统调用,减少了用户态和内核态的切换; read/write需要将数据在内核缓冲区和用户缓冲区间来回拷贝,mmap不用;
更方便:
像操作内存一样读写文件。
注意,对mmap分配的虚拟内存写时,只是写到了物理内存中,并未同步到磁盘,需要调用另一个系统调用msync同步,一般在一段时间的写后调用一次,这样可以合并写,并将随机IO转化为顺序IO,提高性能。
3:共享内存实现进程间通信
依然是对shared模式的利用,普通进程间通过映射同一文件实现进程间通信。父子进程则可以选择映射匿名文件的方式,在父进程中先调用mmap(),然后调用fork(),子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区域进行通信了。
4:分配虚拟内存
12.7 动态内存分配
底层提供了两个系统调用分配虚拟内存:
brk: 伸缩system break指针,即扩展或缩小堆。
堆(heap)是BSS段上方的一块区域,用于内存的动态分配,system break指针指向它的顶端。mmap:更灵活,可以映射任意位置的内存空间,不仅限于堆。
C标准库提供了内存分配器,内部基于上述两个系统调用管理内存的分配和释放,并对上层提供统一的接口:
malloc:分配内存calloc:分配内存并清0realloc:改变一个指针指向的内存块的大小,它经常把内存拷贝到别的地方然后返回新地址free: 释放内存
(alloca是在栈上分配内存)
(以下讨论仅针对只维护heap的分配器,某些分配器当申请大内存时会使用mmap,在堆和栈之间的区域进行分配)
内存分配器通常将heap当作一系列block维护,为了减少系统调用,free时可能只将对应的block送回内存分配器内部维护的内存池中,不会返回给系统;malloc类似。
分配和释放的无序性必然导致碎片的出现,存在两种碎片:
- 内部碎片:
分配器实际分配的block比请求的要大,如规定了block的最短长度/给block加上padding以满足内存对齐。 - 外部碎片:
外部碎片是指,存在若干非连续的小块空闲block,其总量满足分配请求,但没有足够大的单块block。
12.7.1 implicit free list
整个堆由若干连续的block组成,一个block的结构如下:
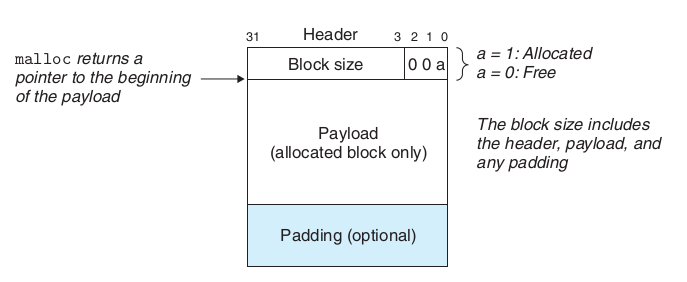
3部分组成:
a. header,定长,保存整个block的大小,以及使用状态;
b. payload,用户实际得到的内存块;
c. padding,为了内存对齐
给定一个block,根据其初始地址和长度,可以快速得到下一个block的位置,组成一个隐式的单向链表:

malloc的实现:
从头开始遍历list,挑选一块足够大的空闲block,切分为两块,并返回指向payload的指针;如果没有满足条件的block,则通过brk扩充堆,O(N)。
挑选free block一般有以下算法:
- first fit,选第一个满足条件的,优点是简单,且分配优先发生在前端,链表后端保存大块的free空间;缺点是前端存在大量的小块碎片,利用率低且增加搜索时间;
- best fit,选所有满足条件中最小的,优点是内存利用率高,缺点是每次搜索都要遍历整个list。
free的实现:
free的参数是指向payload的指针,根据它往前移动可以拿到它所在block的header,并标记为未分配。最后我们需要看情况合并该block前后的空闲块,合并后面空闲块是很容易做到的,只需要根据当前块的大小移动指针即可找到紧邻着的下一个块,但是如何找到前面的块呢?一种方式是从头遍历list,但这样耗时O(N);另一种优化的方式是在现有block的结构上,在末尾增加一个footer,其结构/内容和header一样,如此,free将参数往前移动两个header的距离,就能知道上一个块的信息了。free耗时O(1):
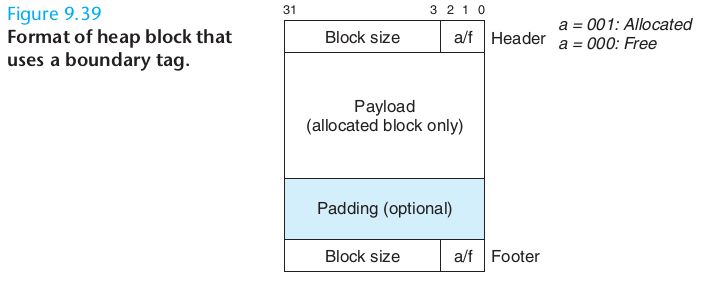
每次free即合并有可能导致空闲块频繁的合并/分裂,因此有些实现将合并的动作推迟到某次malloc失败时,再整个扫描并合并。
12.7.2 buddy system
将一块内存不断等分为一棵二叉树。malloc时深度优先遍历找best-fit的空闲块;free时考察其buddy(如4k等分为两个2k,他们就称为buddy),如果空闲则合并,合并是向上递归的:
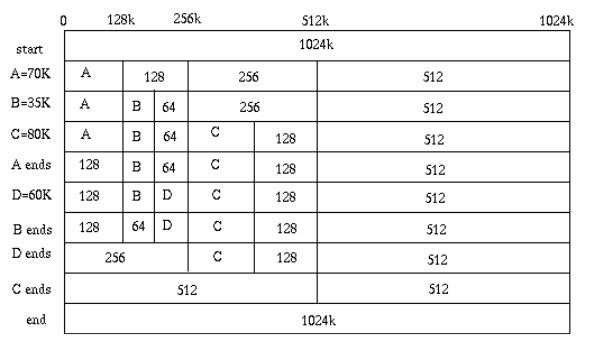
优点:快速,malloc: O(log2N),free: O(log2N)。
缺点:大量的内部碎片,因为需要对请求的内存向上取整。
13 C实现面向对象
OO的3要素:
- 封装:数据和行为的封装,信息的隐藏
- 继承
- 多态
13.1 封装的实现
用struct+函数指针模拟类:
typedef struct _parent{ int name;
void (*printName) (struct _parent* this); // 必须显式将this传入 void (*printSecret)(struct _parent* this);}Parent;
// constructorParent* newParent(int name,int secret);// de-constructorvoid destroyParent(Parent* this);将private信息放在一个不公开定义的struct中,实现信息隐藏:
// parent_private.hstruct ParentPrivate{ int secret;};
// parent.h#include "parent_private.h"struct ParentPrivate;
typedef struct _parent{ int name;
void (*printName) (struct _parent* this); void (*printSecret)(struct _parent* this);
// private attributes,外部仅包含parent.h,不知道ParentPrivate的具体结构 struct ParentPrivate* priv;} Parent;用static在类的实现中模拟private方法和类变量。完整代码如下:
// parent_private.h#ifndef PARENT_PRIVATE_H_#define PARENT_PRIVATE_H_
struct ParentPrivate{ int secret;};
#endif
// parent.h 类的声明#ifndef PARENT_H_#define PARENT_H_#include "parent_private.h"struct ParentPrivate;
typedef struct _parent{ // instance variables int name;
// instance methods void (*printName) (struct _parent* this); void (*printSecret)(struct _parent* this);
// private attributes struct ParentPrivate* priv;} Parent;
// constructorParent* newParent(int name,int secret);// de-constructorvoid destroyParent(Parent* this);#endif
// parent.c 类的实现#include "parent_private.h"#include "parent.h"#include <stdio.h>
void destroyParent(Parent* this){ free(this);}
void printParentName(Parent* this){ printf("name: %d\n",this->name);}
void printParentSecret(Parent* this){ printf("secret: %d\n",this->priv->secret);}
// 私有方法static void privateFn(){}
// 构造器Parent* newParent(int name,int secret){ Parent* p = (Parent*) malloc(sizeof(Parent)); p->name = name;
// 构造私有变量部分 struct ParentPrivate* priv = (struct ParentPrivate*) malloc(sizeof(struct ParentPrivate)); priv->secret = secret; p->priv = priv;
// 设置实例方法 p->printName = printParentName; p->printSecret = printParentSecret;
return p;}
13.2 嵌套struct实现继承
将父类的struct对象放在子类的第一个位置,子类自动获得父类的内容;现在如果想通过子类访问父类的属性,必须通过(o->super).attr的方式。
重写父类结构体中的函数指针,可以实现简单的方法覆盖。
// child.h#ifndef CHILD_H_#define CHILD_H_#include "parent.h"
typedef struct _child{ Parent super; int gender;}Child;
Child* newChild(int name,int secret,int gender);void destroyChild(Child* this);
#endif
// child.c#include "parent.h"#include "child.h"
void destroyChild(Child* this){ free(this);}
void printChildName (Child* this){ printf("name:%d, gender:%d\n",((Parent*)this)->name,this->gender);}
Child* newChild(int name,int secret,int gender){ // 构造父类部分 Parent* super = newParent(name,secret); // override父类的方法 super->printName = printChildName;
Child* this = (Child*)malloc(sizeof(Child)); this->super = *super; this->gender = gender;
return this;}13.3 多态
多态指的是像父类一样调用子类,由于一个Child*指针可以无障碍地强转为Parent*,因此可以如下简单地实现:
void print(Parent* o){ // 可以传入Parent*,也可以传入Child* o->printName(o);}完整的测试代码:
// main.c 测试代码#include "parent.h"#include "child.h"#include <stdio.h>
void print(Parent* o){ o->printName(o);}
int main(void){ Parent* p = newParent(1,2);
// public attribute printf("name is public: %d\n",p->name);
// p->priv->secret; // error,cannot access private attribute
// public methods p->printName(p); p->printSecret(p);
Child* c = newChild(1,2,3); // 测试多态 print(p); // 打印 name: 1 print(c); // 打印 name:1,gender:3
destroyParent(p); destroyChild(c); return 0;}参考资料
《C和指针》
《C专家编程》
《Computer Systems – A Programmer’s perspective》
雨痕的《C语言笔记》
内存管理内幕
Heap allocation: Malloc
Intel x86 Function-call Conventions
C语言面向对象编程(一):封装与继承