Java内存模型和Volatile
1. 什么是 JMM?
JMM屏蔽掉底层不同平台的差异,在语言层面为程序员提供一个抽象的内存模型,它的核心是一系列关于指令乱序的规则,java语言层面上提供的volatile和monitor机制是其中的两个重点。
有两个方面会导致指令的乱序执行:
- 编译器重排序
- CPU 重排序
2. 编译器的重排序
编译器(对 java 而言是 JIT 编译器)在保证 单线程语义正确 的前提下,为了优化性能,可以任意对指令重新排序。这对单线程不会产生影响,但在并发环境下就可能导致问题。
2.1 Compiler Memory Barrier
在其他未提供统一内存模型的语言中(如C),需要使用Compiler Memory Barrier显式告诉编译器停止重排序:以该Barrier为分割线,Barrier上方的指令不可以重排序到下方,反之亦然。
C中,不同的编译器需要不同的指令:
__asm__ __volatile__ ("" ::: "memory"); // GNU
__memory_barrier(); // Intel ECC Compiler
_ReadWriteBarrier(); // Microsoft Visual C++这些指令是针对编译器的,不会对CPU起作用。
2.2 JMM 对编译器重排序的规定
JMM在为编译器重排序定义了如下规则(NO表示不可重排序):
| 1nd \\\ 2nd | Normal Load / Normal Store | Volatile Load / Monitor Enter | Volatile Store / Monitor Exit |
|---|---|---|---|
| Normal Load / Normal Store | NO | ||
| Volatile Load / Monitor Enter | NO | NO | NO |
| Volatile store / Monitor Exit | NO | NO |
Monitor Enter和Monitor Exit分别对应Sychronized块的进入和离开。
简单地说就是在3类地方禁止编译器重排序:
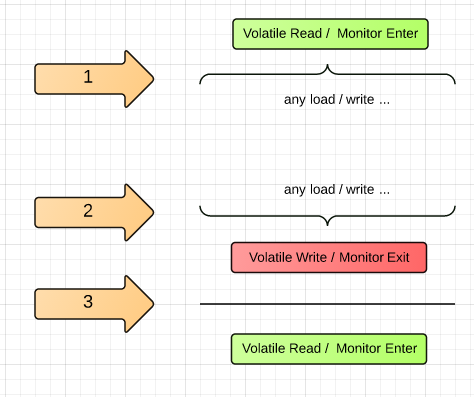
Volatile 读&Sychronized 块的进入与 后续任意读写 不可重排;Volatile 写&Sychronized 块的离开与 之前任意读写 不可重排;Volatile 写&Sychronized 块的离开与后续Volatile 读&Sychronized 块的进入不可重排。
这几处和后面提到的 CPU指令重排序 是一致的。
3. CPU 重排序(Memory Reordering)
Memory Rerdering指的是在 CPU 在执行程序时, 对内存地址的 load 和 store 指令 实际完成的顺序 与 发起指令的顺序 不一致
3.1 为什么会出现Memory Reordering?
CPU 为了避免慢速的内存访问拖累指令的执行速度,一个常用的技巧是:将对cache或内存的load/store指令缓冲至 CPU 内部的 pipeline,对其(异步地)优化后再执行,如重排序(比如先执行命中 cache 的指令,或者将地址相近的指令放在一起执行) / 合并对同一地址的读或写 / 直接从 write buffer 中 load 数据等等,以尽量避免 cache miss,并减少对内存的访问。这是一个生产者消费者模型。
此外,为了充分利用多级流水线,CPU 的 预测执行 speculative execution 机制会根据以往的执行情况,在一个判断条件还没得到结果时预先执行概率大的分支并缓存结果,如果条件判断通过则直接使用该中间结果,这也会导致指令的乱序。
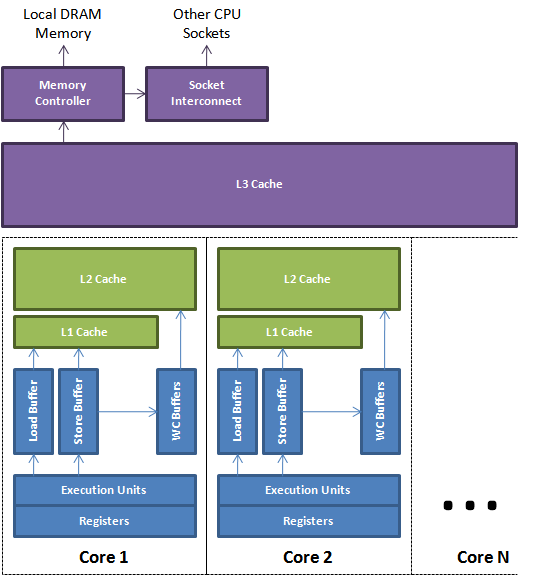
如图所示,CPU 的执行单元与 cache 之间还存在着各种 buffer,load store指令会先进入这些 buffer 中排队。当指令一旦被 flush 到 cache ,MESI 缓存一致性协议将保证数据对所有 CPU 可见。
3.2 什么情况允许Memory Reordering?
CPU 进行 Memory Reordering 的前提是保证单线程下语义的正确性,这和编译器重排序遵循的规则是一样的。更进一步的,对于存在数据依赖性的指令不允许重排序。
数据依赖分下列三种类型:
- 写后读
a = 1;b = a;写一个变量之后,再读这个位置。 - 写后写
a = 1;a = 2;写一个变量之后,再写这个变量。 - 读后写
a = b;b = 1;读一个变量之后,再写这个变量。
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
对于存在控制依赖性的代码也可能发生重排序,如:
if(ready)
b = a * a假如对 ready 的 load 发生了 cache miss,为了不阻塞指令执行, CPU 可能会采用猜测执行的手段,预先 load a,并计算a * a的结果放入 buffer;待 ready 的 load 完成后,如果为 true,再将计算结果取出,执行 b 的 store 动作。
3.3 CPU Memory Barrier
CPU 自身只能保证单线程下的serial 的语义,但在并发程序中,我们经常需要 保证多线程之间内存操作的有序性,这依赖我们手动在合适的地方插入内存屏障,禁止单线程内某种形式的重排序。
Load Store 两两组合,一共存在4种乱序,因此对应的有4种 barrier:
LoadLoadLoadStoreStoreStoreStoreLoadStoreLoad乱序可能导致所谓的 可见性 问题,对同一个内存地址的访问,某些 CPU 在执行Load时允许直接从 StoreBuffer 中取其最近一次的Store返回,显然这可能导致拿到过时的数据;注意,前提是两次指令 访问同一个地址。当前所有主流 CPU 对
StoreLoad barrier的实现都包括了其他3个 barrier 的效果(这不是必须的,只是现实如此),因此,StoreLoad barrier通常也被当做Full Barrier使用。
使用标志位是不同的线程间进行通信的一种常见手段,此时需要借助 Memory Barrier 保证多线程间的有序性。一个简单的例子如下:
// 初始状态
a = 0;
ready = false;
// Thread 1
a = 1;
ready = true;
// Thread 2
if(ready)
print a // 可能打印0
/*
或者:
c = ready
d = a;
*/在这个例子中,Thread 1试图用 ready 传递 a 已经被赋值的信号,但是存在两个问题:
- Thread 1 对 a 和 ready 的
Store动作有可能StoreStore乱序,导致 ready 为 true 时,Thread 2看到的 a 依然是0。因此,在 Thread 1 中必须在 a 和 ready 的store 动作之间插入StoreStore barrier,保证外部在看到 ready 为 true 时,a 必然已被修改; - 即使 Thread 1 保证了 Store 有序,Thread 2 依然可能发生
LoadLoad乱序。对 a 的 Load 操作可能发生在 ready 的 Load 之前,因此下面的执行顺序是有可能的:
Thread 1 Thread 2
========= ===========
Load a (0)
a = 1
<StoreStore barrier>
ready = true
Load ready (true)
判断通过
print a因此,在 Thread 2 中必须用LoadLoad barrier保证 a 和 ready 两个 Load 动作的顺序性。
由此可见,内存屏障 只能保证执行该屏障的 CPU 的内存顺序性,如果两个线程依赖读写某些相同变量进行通信,只在某一端使用屏障是不够的,另一端也必须根据自己的逻辑加上对应的内存屏障。
3.4 硬件内存模型
Memory Model指定了 CPU 允许哪些指令重排序的发生,越多,内存一致性越弱;越少,内存一致性就越强。
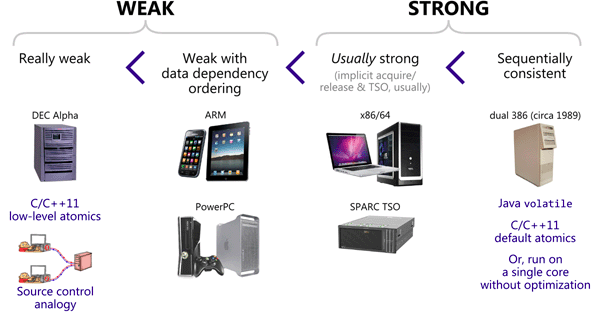
常见的 x86 平台只允许 StoreLoad 乱序,因此它的内存模型属于强一致性。
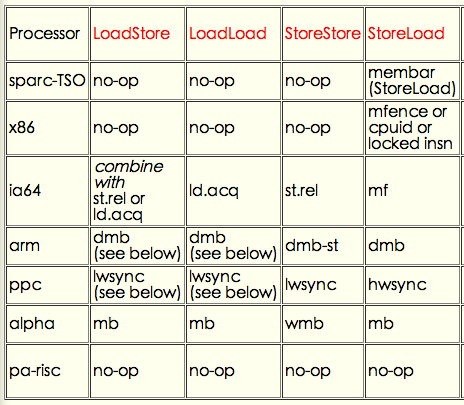
不同平台上这四种 memory barrier 对应的指令如下,其中 x86 因为只支持StoreLoad乱序,所以只提供了StoreLoad Barrier (亦即Full Barrier):
3.5 Read-Acquire barrier 和 Write-Release barrier
在实际应用中,4种按乱序情况的分法太细粒度了,Read-Acquire barrier 、 Write-Release barrier 是一种更粗粒度,也更常用的分类方式;

即:
- Read-Acquire = LoadLoad + LoadStore;
- Write-Release = LoadStore + StoreStore.
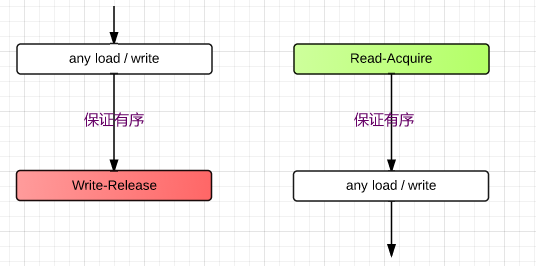
Read-Acquire
具有 Read-Acquire 语义的 Read 操作保证,所有后续的读写只有在该 Read 执行完毕后才能执行。
Write-Release
具有 Write-Release 语义的 Write 操作保证,只有之前的所有读写都已经执行完毕,该 write 才能执行。
Read-Acquire barrier 和 Write-Release barrier 总是成对使用的,保证不同线程间对内存操作的顺序性:
还是举上面的例子,用Read-Acquire和Write-Release barrier 的方式如下:
// 初始状态
a = 0;
ready = false;
// Thread 1
a = 1;
write_release_barrier();
ready = true;
// Thread 2
if(ready){
read_acquire_barrier();
print a
}此时,我们 为 ready 这个变量赋予了 Read-Acquire 和 Write-Release 语义,对它的读或写动作与前后的其他 load/store 动作确立了先后关系. 当 Thread 2 发现 ready 为 true 时,a 的 store 必然已经完成,必然为1; 而 a 的 load 也不会比 ready 的 load 先完成.
Read-Acquire 和 Write-Release 语义也被广泛应用在锁的实现中,加锁 和 释放锁 分别附带了Read-Acquire 和 Write-Release 语义,保证了 加锁 --> load/store 和 load/store --> 释放锁 这两个指令序列之间的偏序关系,这样当某个线程获取了锁时,它可以确信前一个线程在释放锁之前所做的操作已经全部完成了。
接下来会看到,Read-Acquire 和 Write-Release 是 JMM 的核心。
3.6 JMM 对 CPU Memory Reordering 的规则
JMM 定义了单线程内必须遵循如下重排序规则:
| NormalLoad | NormalStore | VolatileLoad / MonitorEnter | VolatileStore / MonitorExit |
|---|---|---|---|
| NormalLoad | |||
| NomalStore | |||
| VolatileLoad / MonitorEnter | LoadLoad | LoadStore | LoadLoad |
| VolatileStore / MonitorExit | StoreLoad |
看上去很复杂,但其实只有两点:
*
Volatile变量 /Monitor具有Read-Acquire & Write-Release语义; *第三行即
Read-Acquire,最后一列即Write-Release;* 在任意两个
Volatile变量 /Monitor的Store->Load/Exit->Enter操作中间必须插入一个StoreLoadbarrier 禁止重排序; 这同时也解决了单个 volatile 变量 / Monitor 可能出现的可见性问题 。*可见性问题已经在3.3描述过了.
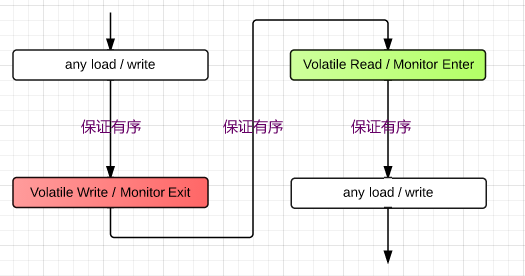
JMM cookbook 中提到了一种可能的实现。编译器很多时候无法知道确切的Load / Store 指令顺序,比如在一个方法 return 之前对一个 Volatile 变量 write 了,因此一个策略是采取悲观策略,在每个可能需要禁止某种重排序的地方都加上对应的 barrier:
- 在每个
Volatile Read / Monitor Enter后加上LoadLoad&LoadStorebarrier,亦即Read-Acquirebarrier; - 在每个
Volatile Write / Monitor Exit前加上StoreStore&LoadStorebarrier,亦即Write-Releasebarrier; - 在每个
Volatile Write / Monitor Exit后加上StoreLoadbarrier(也可以在每次 Read 前加上,但 Write 出现的几率显然要低的多)。
当然,编译器会做许多别的优化,比如合并 barrier 之类的,而且很大一部分的 barrier 对应到硬件指令时是空操作。
这个策略在 openjdk 的 C1 编译器 (c1_LIRGenerator.cpp) 中得到了印证:
//------------------------field access--------------------------------------
// Comment copied form templateTable_i486.cpp
// ----------------------------------------------------------------------------
// Volatile variables demand their effects be made known to all CPU's in
// order. Store buffers on most chips allow reads & writes to reorder; the
// JMM's ReadAfterWrite.java test fails in -Xint mode without some kind of
// memory barrier (i.e., it's not sufficient that the interpreter does not
// reorder volatile references, the hardware also must not reorder them).
//
// According to the new Java Memory Model (JMM):
// (1) All volatiles are serialized wrt to each other.
// ALSO reads & writes act as aquire & release, so:
// (2) A read cannot let unrelated NON-volatile memory refs that happen after
// the read float up to before the read. It's OK for non-volatile memory refs
// that happen before the volatile read to float down below it.
// (3) Similar a volatile write cannot let unrelated NON-volatile memory refs
// that happen BEFORE the write float down to after the write. It's OK for
// non-volatile memory refs that happen after the volatile write to float up
// before it.
//
// We only put in barriers around volatile refs (they are expensive), not
// _between_ memory refs (that would require us to track the flavor of the
// previous memory refs). Requirements (2) and (3) require some barriers
// before volatile stores and after volatile loads. These nearly cover
// requirement (1) but miss the volatile-store-volatile-load case. This final
// case is placed after volatile-stores although it could just as well go
// before volatile-loads.
// volatile store
void LIRGenerator::do_StoreField(StoreField* x) {
// Write-Release barrier
if (is_volatile && os::is_MP()) {
__ membar_release();
}
// Store
...
volatile_field_store(value.result(), address, info);
...
// StoreLoad barrier,这里直接写作 membar 的原因是大部分平台上 storeload barrier 被实现为一个 full barrier
if (is_volatile && os::is_MP()) {
__ membar();
}
}
// volatile load
void LIRGenerator::do_LoadField(LoadField* x) {
// Load
...
volatile_field_load(address, reg, info);
...
// Read-Acquire barrier
if (is_volatile && os::is_MP()) {
__ membar_acquire();
}
}
3. JMM的其他方面
- 原子性,JMM 规定基本类型的 load/store 必须是原子的;
Volatile变量不允许使用寄存器分配。- final 变量??
4. 总结
volatile的作用:保证线程A的内存操作被线程B观察时,是有序的。单线程内,编译器、CPU会出于各种原因乱序完成指令,虽然本线程内的逻辑依然是正确的,但外部线程观察到的指令生效的顺序不可保证,volatile就是解决这个问题的。- 什么时候用
volatile? – 当一个变量被多线程访问, 且会被其中某些线程 write 时, 用volatile.
5. 参考资料
- The JSR-133 Cookbook
- 何登成的《CPU Cache and Memory Ordering.ppt》
- 无锁化编程
- Acquire and Release Semantics
- Memory Ordering at Compile Time
- Memory Barriers/Fences
- Java Memory Model Under The Hood
- Memory Ordering in Modern Microprocessors, Part II
- CPU Cache Flushing Fallacy
- Weak vs. Strong Memory Models
- 深入理解Java内存模型 系列文章
附:StoreLoad 乱序导致 Peterson 算法 失效
这不属于通用问题,而是依赖代码的逻辑。