Cache 相关理论
1. 什么是cache
从数据源查询结果开销大,在其之上部署一层访问快的存储空间,保存常用的查询结果,避免每次查询直接落到数据源,增加时间开销/数据源负荷。
cache VS buffer
同样的都是位于最终数据源之上的,cache侧重读,buffer侧重写。
但很多时候,cache同时也担任着缓冲写的功能,这时经常看到cache和buffer这两个术语的混用。
2. eviction(淘汰策略)
当cache满了而新的entry需要load进来时,必然需要evict老的entry腾出位置,常见的淘汰策略有:
2.1 FIFO
略
2.2 LFU
Least Frequency Used,淘汰 使用频率最低 的。
为每个entry维护一个计数器,每命中一次+1,淘汰时找最小的。
劣势在于:
- 需要额外的空间维护frequency;
- 不够 adaptive。Cache是有时效性的,当前一段时间的热点数据可能和较前的热点数据完全不同,LFU会优先evict当前热点数据(freqency未增加到足以“抗衡”老entry)。
2.3 LRU
Least Recently Used,淘汰 最近命中时间最早 的entry,即 最久没有被使用过 的。
直接的实现需要为每个entry维护最后一次命中的时刻,但有一个tricky的做法:
每次命中将entry移到队列头部,淘汰时找队尾即可,该元素即最久没有使用过的元素
该算法既考虑到了时效性,又容易实现,是用的最多的evict策略。
2.3.1 JDK自带的LRU实现
JDK中的LinkedHashMap默认维护的是元素的插入顺序 insertion-order,但它也提供了一个可选特性,即维护元素的(最近一次)访问顺序 access-order。该方法在每次get()命中后将该元素移动到head,这正是LRU算法需要的。
此外,removeEldestEntry()方法在每次put()后判断是否需要evict队尾。基于这两个特性可以实现一个简单的定长LRU cache:
public class LRUCache extends LinkedHashMap{
private static final int MAX_ENTRIES = 3;
public LRUCache2(){
super(MAX_ENTRIES+1, .75F,true); // 最后一个参数为true,表示维护的是access order 而非 insertion order
}
// This method is invoked by put and putAll after inserting a new entry into
// the map. It allows the map to have up to 3 entries and then
// delete the oldest entry each time a new entry is added.
protected boolean removeEldestEntry(Map.Entry eldest){
return this.size() > MAX_ENTRIES;
}
}2.4 Auto*
自己不主动evict,利用JVM的SoftReference,在内存不够时通过GC回收。
也可结合LRU,设置两级Cache,第一级使用LRU算法,淘汰后进入第二级;第二级使用Automic算法。
java中不同类型的Reference:
Soft/Weak/Phatom 引用类型
- Soft
内存不够用,或get()很少调用时被GC掉。实现Cache的一个好选择,将LRU算法交给JVM了。- Weak
每次GC时都会回收。- Phantom
get()永远返回null,比Weak更弱,一般继承PhantomReference存储额外的数据,并配合ReferenceQueue使用,在对象回收后做额外的清理动作。Finalize
- GC只保证释放对象占用的内存,外部资源需要自己管理;
- 只能运行一次。可以rescue自己,但再次回收时不会执行第二次。
ReferenceQueue
- 3种弱引用在构造时可以指定一个ReferenceQueue,当referent(可以)被回收时,该Reference被加入队列。
- soft/weak在加入队列时,其 referent 的 finalize 方法未被执行,对象只是可以GC,但并未回收;而 phantom 出现在队列时,其 referent 已经完全被回收了,finalize 方法也执行过了。
参考
3. expire
过期,让entry自动失效的一种机制。
3.1 time to live (ttl)
上次read经过的时间。
3.2 time to idle (tti)
上次create 或 update经过的时间。侧重点在数据的正确性,经常用这种方式保证cache与数据源的一致性(一段不一致窗口后)。
一般不用定时器实现expire,而在read/update时判断,lazy。
4. 分布式缓存
distributed分散压力,实现scale-out。单独来看,常见的(数据类产品的)分布式拓扑有两种:* replication (复制) * 和 * shard (分片) *
CAP
在数据共享的系统的三项属性当中,数据一致性、系统可用性 和 对网络分区的耐受性,在任何给定时间内都只能达成其中的两项”。由于“在较大分布规模的系统中,网络分区是给定的”,因此一致性和可用性必有一项需要放宽
4.1 replication
一份数据存在在不同的节点上,依靠复制保证数据的一致性。一致性换可用性。
优:
- 更高的可用性。(分区耐受性)
劣:
- 弱/最终一致性,复制导致必然有一个不一致的时间窗口。实现强一致性会降低性能,复杂度上升。当数据在多个地方被写时,还要考虑并发写。
目的:读负载均衡 / 多级缓存(本地缓存) / 实现高可用。
- web 容器复制session;
- cpu L1 cache;
- mysql 读写分离;
- mysql dual-master 高可用;
EHCache 支持 replication 风格的分布式缓存,每个web app节点在自己的进程内有一个本地缓存,这些本地 cache 通过 RMI/JMS/JGroups 等机制进行同步或异步的复制,保证不同节点上 cache 的一致性。
分布式缓存的另一种同步方式是 invalidate queue (这也是大部分 cpu cache 采用的策略),发生改变的 cache 向其他节点发送 invalidate 信号使其失效,使用时再从数据源加载。
4.2 shard
将数据路由到不同的节点上,每个节点负责部分数据的读写,一份数据只在一个节点上。可用性换一致性。
通常会对每个shard用replication分担读压力/保证HA。
Memcached本身是一个非常简单的内存KV系统,没有复制/事务等功能,它的shard是通过客户端实现的,客户端实现路由/节点权重等,每个节点不会意识到集群中其他节点的存在。
consistent hash
提到缓存的shard就绕不开一致性hash算法。
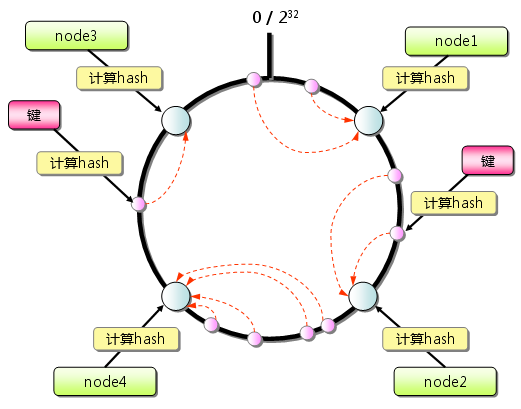
传统取模hash当节点变化后,数据和节点间的映射关系将剧烈改变,引起大量的缓存失效,一致性hash的目的就是 节点数量变化后,减少数据在节点间的迁移。一致性hash的工作方式如下:
- 对节点hash,映射到0-2^32次方的圆上;
- 对数据(key)hash,映射到相同的圆上;
- key分配的节点为 从key出发,顺时针找到的第一个节点
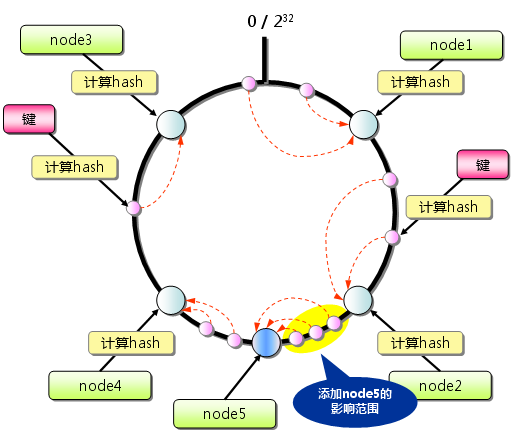
增加一台服务器(node5)后,影响的只有小部分数据,最大限度地抑制了键的重新分布:
此外,很多consistent hash的实现采用了虚拟节点的优化方式尽可能地让数据分布均匀(负载均衡)。如果用直接hash节点,节点数量少时会在环形空间上分布不均,造成某些节点上的数据过多。虚拟节点 的本质是扩大节点的规模,规模越大,分布越均匀,负载越平衡;它将一个真实节点映射到N个虚拟节点,数据的查找要经历两个映射:key <–> 虚拟节点 <–> 真实节点。
5. 写时Cache与后端的同步
在某些系统中,如 cpu cache,所有写的动作都必须先落在 cache,然后再传播到后端数据源;而在另一些场景中,如 web 应用,cache 大部分情况下只用作查询缓存,只会失效而不会更新。
5.1 先写 cache
write-back
只写cache,不写数据源。当cache被淘汰时再同步,或在某个时刻统一flush dirty cache。优点在于可以减小对数据源的压力(合并update/缓冲写高峰);缺点在于二者之间的delay及其造成的数据不一致/事务被推迟/动作的顺序不能保证/cache挂了造成数据丢失等等。
适合逻辑简单的/不需要事务/不要求精确的统计任务,如计数器,对缓解DB压力有奇效。
write-through
每次写cache时同时写数据源。优点是能够保证数据源数据的实时性,缺点是频繁的随机IO。
此外,在web环境下,这种方式要求 cache 支持事务,在数据源事务进行的过程中 cache 随之 commit/rollback,否则会出现脏数据。
手动写cache保证(较强)一致性的方式一来要求cache支持事务,二来增加了系统/代码复杂度,因此不太会在web应用中普适性地应用。另一方面,cache中存储的大部分是query的结果,很多时候允许存在一定程度的不一致,因此通常不会手动更新 cache。
write-through策略下对IO的一种优化
write-through时,将改动顺序flush到日志文件中,这一步是顺序IO;- 当日志文件满时,再将日志文件中记录的改动同步到后端数据源,这一步可以做很多优化,比如合并
write操作(减少IO),或者将write分组(将随机IO转为顺序IO)。总体来说,IO的总量增多了,但这种 用
异步IO代替同步IO,从而将随机IO转变为顺序IO的策略反而是提高了IO性能。******* (机械硬盘因为依赖磁头的移动,因此
随机IO性能要差于顺序IO)InnoDB就是用这种方式,利用事务日志文件对数据/索引缓存的IO进行优化。可以参考:
- 《High Performance MySQL, 3rd Edition》Chapter 8 / InnoDB IO Configuration
- 《MySQL性能调优与架构设计–全册》11.2.3 数据存储优化
5.2 不写cache
invalidate cache
更新数据源后手动 invalidate 相关 cache,下次查询造成 cache miss,从 DB 中 load 最新数据。这种方法的不一致窗口也较短。
利用 cache 的 expire 机制
更新数据源后不管cache,利用cache的expire(ttl)自动在某个时刻失效,适合对实时性要求不高的场景。